Spring WebFlux 中的并发
1、简介
本文将带你了解 Spring WebFlux 响应式应用中的并发。
2、响应式编程的动机
一个典型的 Web 应用由多个复杂的交互部分组成。其中许多交互在本质上是阻塞性的,例如那些涉及数据库调用以获取或更新数据的交互。而其他几个部分则是独立的,可以 并发 执行,也可能是 并行 执行。
并发是多个任务在同一时间段内交替执行,而并行是多个任务同时执行。并发关注的是任务的调度和切换,以提高系统的效率和响应性,而并行关注的是任务的同时执行,以提高计算速度和性能。
例如,用户对 Web 服务器的两个请求可以由不同的线程处理。在多核平台上,这对整体响应时间有明显的好处。因此,这种并发模型被称 thread-per-request(每个请求一个线程)模型:
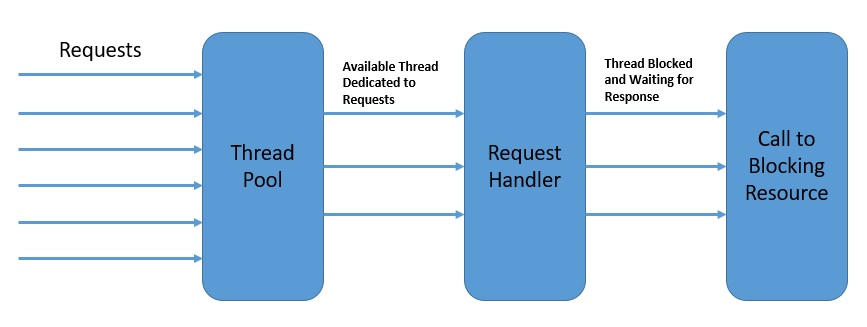
如上图,每个线程一次处理一个请求。
虽然基于线程的并发为我们解决了部分问题,但却无法解决单个线程内的大部分交互仍然是阻塞的这一事实。此外,在 Java 中使用原生线程来实现并发时,还需要付出上下文切换的巨大代价。
与此同时,随着 Web 应用面临的请求越来越多,thread-per-request 模式开始无法满足人们的期望。
因此,我们需要一种并发模型,它可以帮助我们用相对较少的线程数处理越来越多的请求。这也是采用响应式编程的主要动机之一。
3、响应式编程中的并发
响应式编程可以帮助我们根据数据流和变化的传播来构建程序。在完全无阻塞的环境中,这可以让我们实现更高的并发性和更好的资源利用率。
然而,响应式编程是否完全摒弃了基于线程的并发?虽然这种说法有些激烈,但响应式编程肯定与使用线程实现并发的方法截然不同。响应式编程带来的根本区别在于 异步。
换句话说,程序流程从一连串同步操作转变为异步事件流。
例如,在响应式模型下,对数据库的读取调用不会在获取数据时阻塞调用线程。调用会立即返回一个发布者(Publisher),其他人可以订阅该发布者。订阅者(Subscriber)可以在事件发生后对其进行处理,甚至可以自己进一步生成事件:
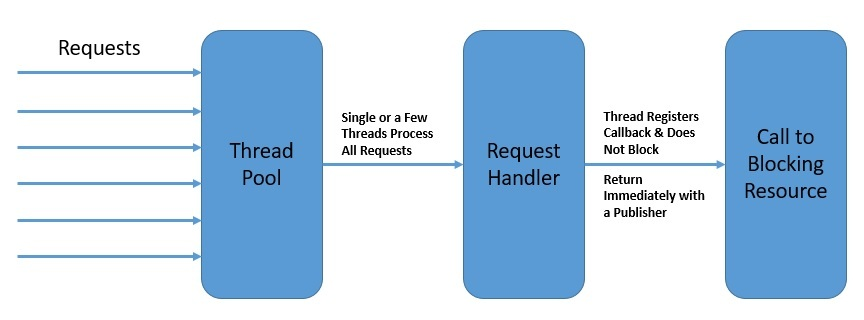
最重要的是,响应式编程并不强调应该生成和消耗哪个线程事件。相反,它强调的是将程序构造成异步事件流。
这里的发布者和订阅者不需要属于同一个线程。这有助于我们更好地利用可用线程,从而提高整体并发性。
4、Event Loop
Event Loop(事件循环)模型是一种用于服务器的响应式异步编程模型:
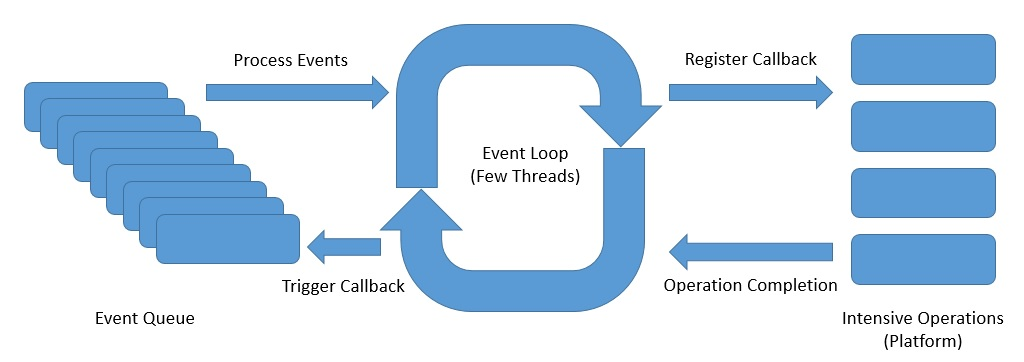
上图是一个事件循环的抽象设计,展示了响应式异步编程的思想:
- Event Loop 在单个线程中连续运行,我们可以根据可用内核的数量设置多个 Event Loop。
- Event Loop 按顺序处理来自事件队列的事件,并在向平台注册回调后立即返回。
- Platform(平台)可以触发操作的完成,如数据库调用或外部服务调用。
- Event Loop 可在 operation(操作)完成通知时触发 callback(回调),并将结果发回给原始调用者。
包括 Node.js、Netty 和 Ngnix 在内的许多平台都实现了 Event Loop 模型。与 Apache HTTP 服务器、Tomcat 或 JBoss 等传统平台相比,它们具有更好的可扩展性。
5、用 Spring WebFlux 进行响应式编程
对响应式编程及其并发模型有了足够的了解后,来看看 Spring WebFlux。它是 Spring 在 5.0 版本中添加的响应式 Web 框架。
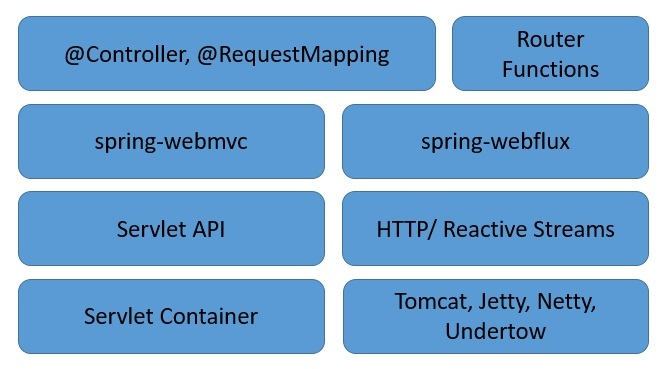
你可以看到,Spring WebFlux 与 Spring 中的传统 Web 框架并行,并不一定会取代它。
这里有几个要点需要注意:
- Spring WebFlux 通过函数路由扩展了传统的基于注解的编程模型。
- 此外,它还将底层 HTTP 运行时与 Reactive Streams API 相适配,使得运行时之间可以互操作。
- 它能够支持各种响应式运行时,包括 Tomcat、Reactor、Netty 或 Undertow 等 Servlet 3.1+ 容器。
- 最后,它还包括 WebClient,这是一个用于 HTTP 请求的响应式非阻塞客户端,提供函数式和 Fluent 风格的 API。
6、支持的运行时的线程模型
如前所述,响应式程序倾向于只使用几个线程并充分利用它们。不过,线程的数量和性质取决于选择的实际 Reactive Stream API 运行时。
要说明的是,Spring WebFlux 可以通过 HttpHandler 提供的通用 API 适应不同的运行时。该 API 是一个简单的接口,只有一个方法,提供了对不同服务器 API(如 Reactor Netty、Servlet 3.1 API 或 Undertow API)的抽象。
来看看其中几种软件所采用的线程模型。
WebFlux 默认的服务器是 Netty,你也可以使用其他任何受支持的服务器,如 Tomcat。只需要在 pom.xml 中正确配置依赖即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-reactor-netty</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>
有多种方式观察在 Java 虚拟机中创建的线程,也可以直接从线程类本身提取线程,这更简单:
Thread.getAllStackTraces()
.keySet()
.stream()
.collect(Collectors.toList());
6.1、Reactor Netty
如上所述,Reactor Netty 是 Spring Boot WebFlux Starter 中的默认嵌入式服务器。来看看 Netty 默认创建的线程。
首先,不添加任何其他依赖,也不会使用 WebClient。因此,如果启动使用 Spring Boot Starter 创建的 Spring WebFlux 应用,就会看到它创建的一些默认线程:
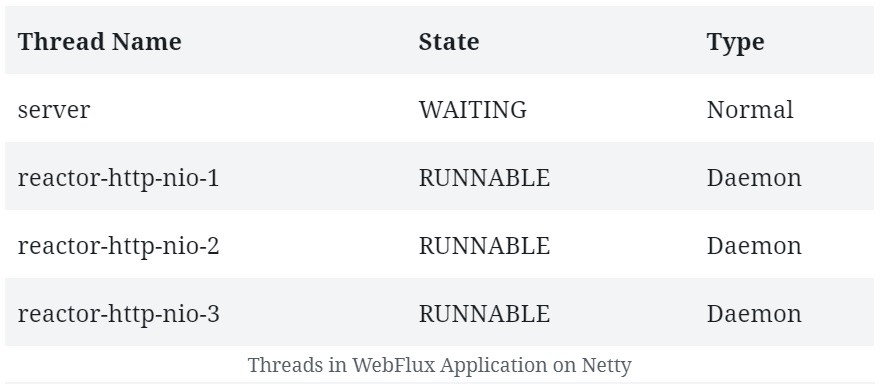
注意,除了用于服务器的普通线程外,Netty 还会生成大量用于处理请求的工作线程。这些线程数量通常是可用的 CPU 内核数量。这是在四核机器上的输出结果。还有一些典型的 JVM 环境下的管理线程,但在这里它们并不重要。
Netty 使用 Event Loop 模型,以异步响应式的方式提供高度可扩展的并发性。来看看 Netty 如何利用 Java NIO 实现 Event Loop,从而提供这种可扩展性:
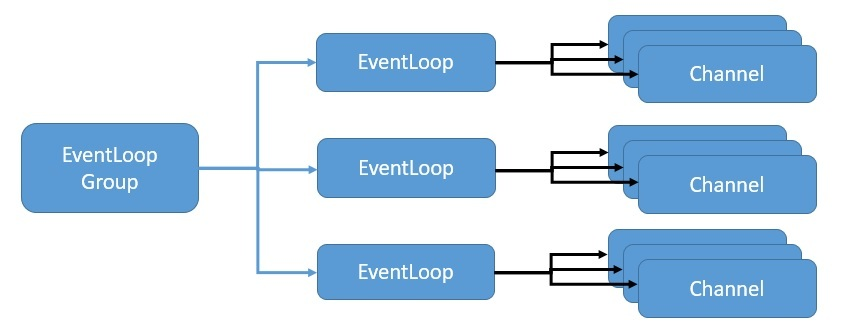
如上,EventLoopGroup 管理一个或多个必须持续运行的 EventLoop。因此,不建议创建超过可用内核数量的 EventLoop。
EventLoopGroup 还为每个新创建的 Channel 分配一个 EventLoop。因此,在 Channel 的整个生命周期内,所有操作都由同一个线程执行。
6.2、Apache Tomcat
Spring WebFlux 也支持传统的 Servlet 容器(如 Apache Tomcat)。
WebFlux 依赖于 Servlet 3.1 API 和非阻塞 I/O。虽然它在底层适配器后面使用了 Servlet API,但 Servlet API 并不能直接使用。
来看看在 Tomcat 上运行的 WebFlux 应用会有哪些线程:
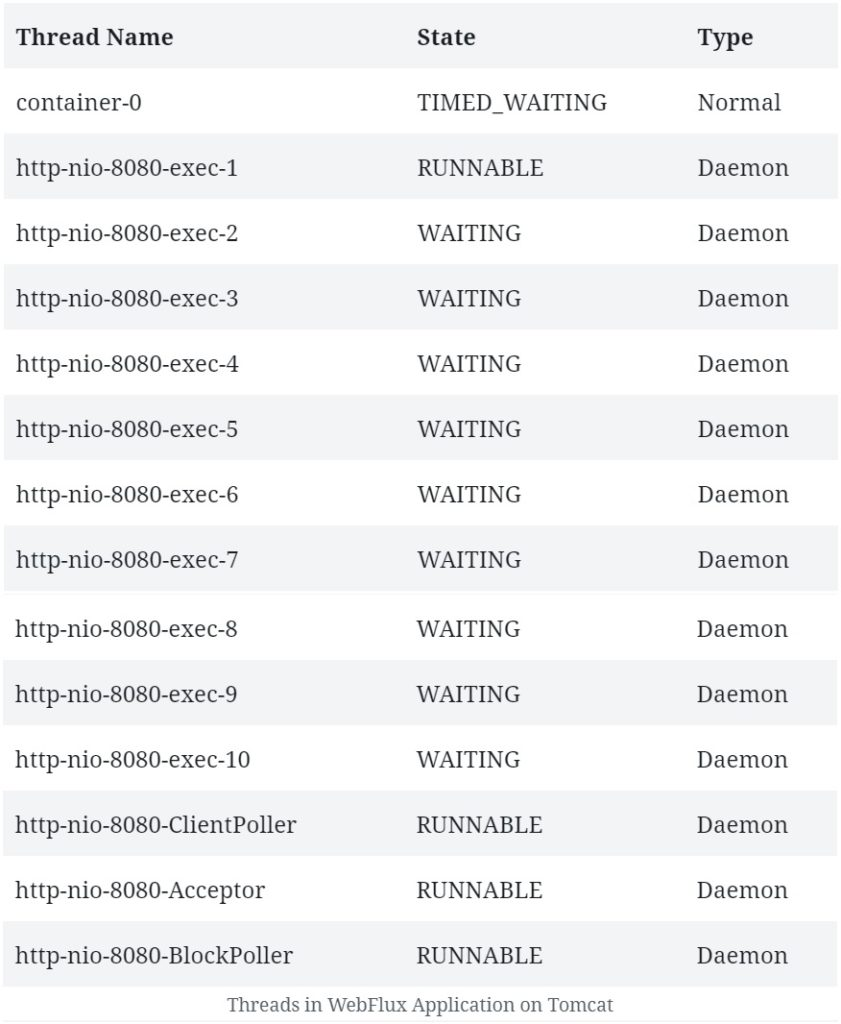
你可以看到,这里的线程数量和类型与之前观察到的截然不同。
首先,Tomcat 启动时会有更多的工作线程,默认为 10 个。当然,还会看到一些 JVM 和 Catalina 容器特有的内部线程,但在本文中可以忽略这些线程。
我们需要先了解 Tomcat 与 Java NIO 的架构,才能将其与上面看到的线程联系起来。
Tomcat 5 及以后版本在其 Connector(连接器)组件中支持 NIO,该组件主要负责接收请求。
另一个 Tomcat 组件是 Container(容器)组件,它负责容器管理功能。
在这里,重点关注的是 Connector 组件为支持 NIO 而实现的线程模型。它由 Acceptor、Poller 和 Worker 组成,是 NioEndpoint 模块的一部分:
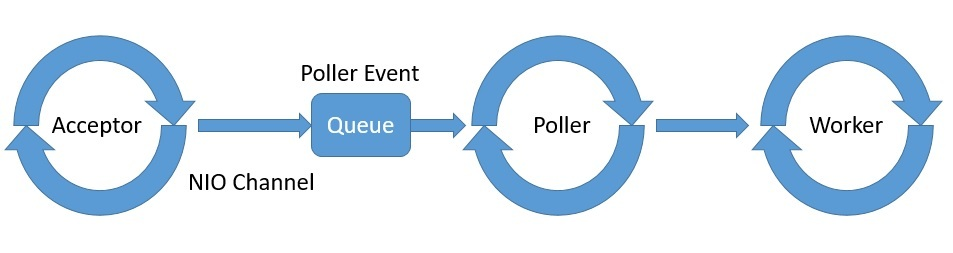
Tomcat 会为 Acceptor、Poller 和 Worker 生成一个或多个线程,通常还会有一个专用于 Worker 的线程池。
对 Tomcat 架构的详细讨论超出了本文的范围,但我们现在应该有足够的了解来理解我们之前看到的线程。
7、WebClient 的线程模型
WebClient 是 Spring WebFlux 中的响应式 HTTP 客户端。可以在需要基于 REST 的通信时使用它,从而创建端到端的响应式应用。
正如之前所看到的,响应式应用只需几个线程即可运行,因此应用的任何部分都不会阻塞线程。因此,WebClient 在帮助我们实现 WebFlux 的潜力方面发挥着至关重要的作用。
7.1、使用 WebClient
使用 WebClient 也很简单。不需要包含任何特定的依赖,因为它是 Spring WebFlux 的一部分。
创建一个简单的 REST 端点,它返回一个 Mono:
@GetMapping("/index")
public Mono<String> getIndex() {
return Mono.just("Hello World!");
}
然后,使用 WebClient 来调用这个 REST 端点,并被动地消费数据:
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.doOnNext(s -> printThreads());
在这里,还打印了使用前面介绍的方法创建的线程。
7.2、理解线程模型
那么,线程模型在 WebClient 中是如何工作的呢?
毫不疑问,WebClient 也使用 Event Loop 模型实现并发。当然,它依赖于底层运行时提供必要的基础架构。
如果我们在 Reactor Netty 上运行 WebClient,它将共享 Netty 用于服务器的 Event Loop。因此,在这种情况下,我们可能不会注意到创建的线程有什么不同。
不过,WebClient 也支持 Servlet 3.1+ 容器(如 Jetty),但其工作方式有所不同。
如果我们比较一下运行 Jetty 的 WebFlux 应用上创建的线程(有 WebClient 和没有 WebClient),就会发现多了几个线程。
在这里,WebClient 必须创建其 Event Loop。因此,可以看到该 Event Loop 创建的固定数量的处理线程:
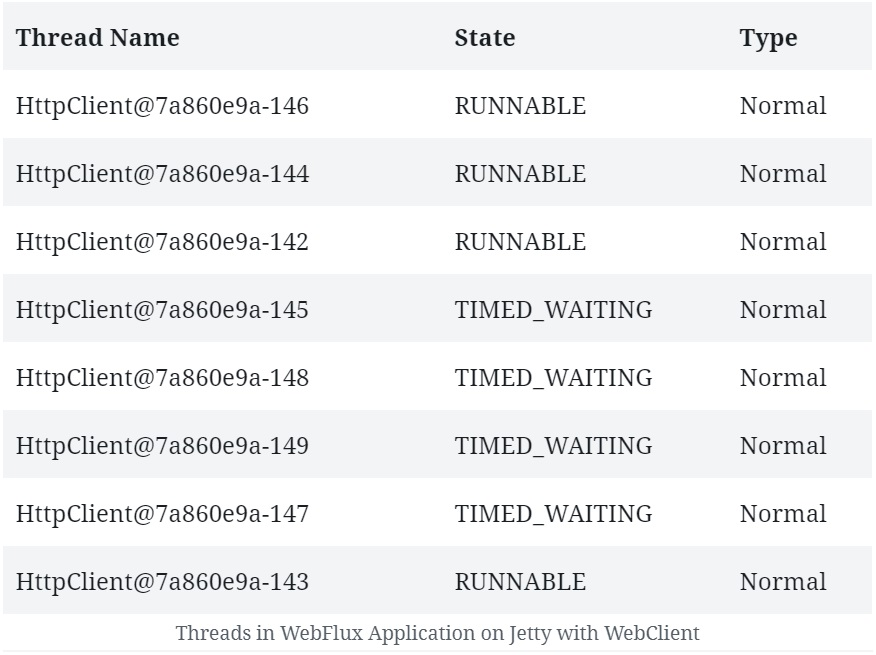
在某些情况下,为客户端和服务器设置独立的线程池可以提供更好的性能。虽然这不是 Netty 的默认行为,但如果需要,可以为 WebClient 声明一个专用的线程池。
8、数据访问库的线程模型
正如之前所说,即使是一个简单的应用,通常也由几个需要 “连接” 的组件组成。
这些组件的典型例子包括数据库和 Message Broker。其中许多现有的客户端库仍然是阻塞的,但这种情况正在迅速改变。
现在有几种数据库提供用于连接的响应式客户端库。其中许多库在 Spring Data 中可用,也可以直接使用其他库。
来看看这些库使用的线程模型。
8.1、Spring Data MongoDB
Spring Data MongoDB 基于 MongoDB Reactive Streams 驱动 为 MongoDB 提供响应式 Repository 支持。最值得注意的是,该驱动完全实现了 Reactive Streams API,可提供具有非阻塞背压(back-pressure)的异步流处理。
添加 pring-boot-starter-data-mongodb-reactive 依赖,即可在 Spring Boot 中使用 MongoDB 响应式 Repository:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>
创建一个 Repository,并使用它以非阻塞的方式在 MongoDB 上执行一些基本操作:
public interface PersonRepository extends ReactiveMongoRepository<Person, ObjectId> {
}
.....
personRepository.findAll().doOnComplete(this::printThreads);
那么,当我们在 Netty 服务器上运行此应用时,会看到什么样的线程呢?
毫无疑问,不会看到太大的区别,因为 Spring Data Reactive Repository 使用的是与服务器相同的 Event Loop。
8.2、Reactor Kafka
Spring 目前仍在建设全面支持响应式 Kafka 的过程中。然而,在 Spring 之外确实有其他可用的选择。
Reactor Kafka 是基于 Reactor 的 Kafka 响应式 API。Reactor Kafka 可以使用函数式 API 发布和消费消息,也可以使用非阻塞背压。
首先,需要在应用中添加所需的依赖,以使用 Reactor Kafka:
<dependency>
<groupId>io.projectreactor.kafka</groupId>
<artifactId>reactor-kafka</artifactId>
<version>1.3.10</version>
</dependency>
以非阻塞的方式向 Kafka 发送消息:
// producerProps:标准 Kafka 生产者配置 Map
SenderOptions<Integer, String> senderOptions = SenderOptions.create(producerProps);
KafkaSender<Integer, String> sender = KafkaSender.create(senderOptions);
Flux<SenderRecord<Integer, String, Integer>> outboundFlux = Flux
.range(1, 10)
.map(i -> SenderRecord.create(new ProducerRecord<>("reactive-test", i, "Message_" + i), i));
sender.send(outboundFlux).subscribe();
同样,也可以以非阻塞的方式从 Kafka 中获取消息:
// consumerProps:标准 Kafka 消费者配置 Map
ReceiverOptions<Integer, String> receiverOptions = ReceiverOptions.create(consumerProps);
receiverOptions.subscription(Collections.singleton("reactive-test"));
KafkaReceiver<Integer, String> receiver = KafkaReceiver.create(receiverOptions);
Flux<ReceiverRecord<Integer, String>> inboundFlux = receiver.receive();
inboundFlux.doOnComplete(this::printThreads)
上述代码非常简单,订阅了 Kafka 中的 reactive-test 主题,并收到了 Flux 消息。
其创建的线程如下:
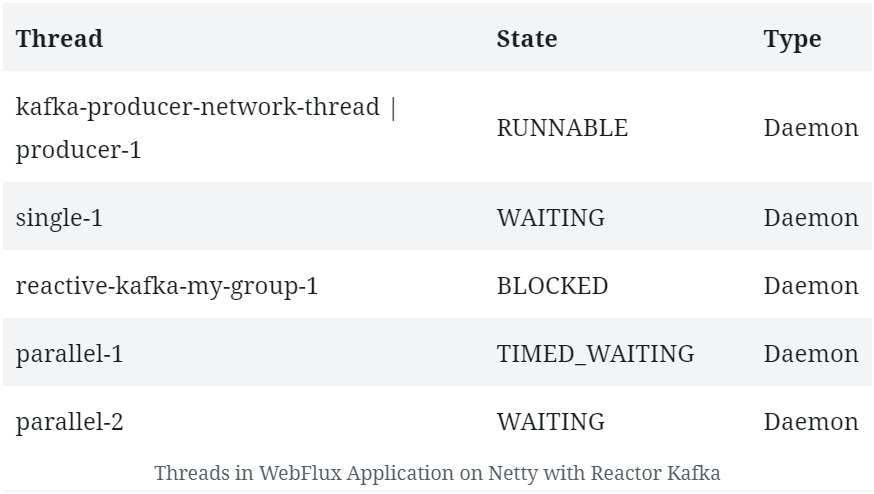
可以看到一些非典型的 Netty 服务器线程。
这表明 Reactor Kafka 管理着自己的线程池,其中有几个工作(worker)线程专门参与 Kafka 消息的处理。当然,还会看到其他一些与 Netty 和 JVM 相关的线程,这些我们都可以忽略不计。
Kafka 生产者使用单独的网络线程向 Broker 发送请求。此外,它们还通过单线程池调度器(single-threaded pooled scheduler)向应用发送响应。
而 Kafka 消费者则是每个消费者组有一个线程,它会阻塞以监听传入的消息。然后,传入的消息会被调度在不同的线程池中处理。
9、WebFlux 中的调度选项
到目前为止,我们已经看到,在完全非阻塞的环境中,只需使用少量线程,响应式编程就发挥了出色的作用。但这也意味着,如果确实存在阻塞的部分,它将导致性能严重下降。这是因为阻塞操作可能会完全冻结 Event Loop。
那么,响反应式编程中,我们该如何处理长期运行的进程或阻塞操作呢?
老实说,最好的办法就是避开它们。然而,这并不总是可行的,我们可能需要为应用的这些部分制定专门的调度策略。
Spring WebFlux 提供了一种在 Data Flow Chain 之间将处理切换到不同线程池的机制。这可以让我们精确控制某些任务的调度策略。当然,WebFlux 是基于线程池抽象(即底层 Reactive 库中的调度器)来提供这种功能的。
9.1、Reactor
在 Reactor 中,Scheduler 类定义了执行模型以及执行的位置。
Schedulers 类提供了许多执行上下文(Execution Context),如 immediate、single、elastic 和 parallel。它们提供了不同类型的线程池,可用于不同的工作。此外,还可以使用已有的 ExecutorService 创建自己的 Scheduler。
Schedulers 提供了多种执行上下文,而 Reactor 也为切换执行上下文的不同方法。这些方法就是 publishOn 和 subscribeOn。
我们可以在 Chain(调用链)中的任何位置将 publishOn 与 Scheduler 一起使用,Scheduler 会影响所有后续操作符。
虽然可以在 Chain 中的任何位置使用 subscribeOn 和 Scheduler,但它只会影响发送源的上下文。
回想一下,WebClient 在 Netty 上默认共享与服务器相同的 Event Loop。然而,我们可能有合理的理由为 WebClient 创建一个专用的线程池。
来看看如何在 Reactor(WebFlux 的默认 Reactive 库)中实现这一点:
Scheduler scheduler = Schedulers.newBoundedElastic(5, 10, "MyThreadGroup");
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.publishOn(scheduler)
.doOnNext(s -> printThreads());
之前,我们没有观察到在有 WebClient 和没有 WebClient 的 Netty 上创建的线程有什么不同。然而,如果现在运行上面的代码,我们可以观察到一些新的线程被创建:
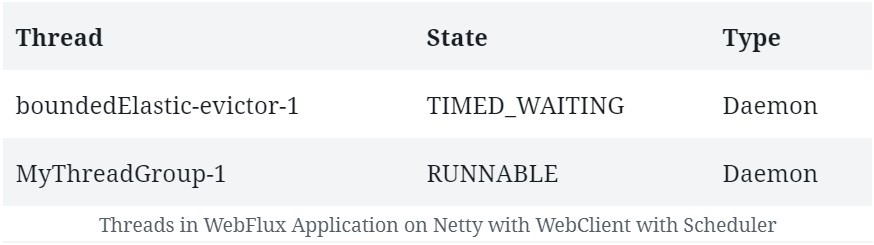
在这里,我们可以看到作为 “bounded elastic thread pool”(有界弹性线程池) 一部分创建的线程。一旦订阅,WebClient 的响应就会在这里发布。
这样,主线程池就可以处理服务器请求了。
9.2、RxJava
RxJava 的默认行为与 Reactor 并无太大区别。
Observable 以及在其上应用的操作符链(Chain)会在订阅被调用的同一线程上执行工作并通知观察者。此外,RxJava 和 Reactor 一样,提供了将预定的或自定义的调度策略引入到链中的方法。
RxJava 还有一个 Schedulers 类,它为 Observable 链提供了多种执行模型。其中包括 new thread、immediate、trampoline、io、computation 和 test。当然,它还允许从 Java Executor 中定义一个 Scheduler。
此外,RxJava 还提供了两种扩展方法来实现这一目标,即 subscribeOn 和 observeOn。
subscribeOn 方法通过指定一个不同的 Scheduler 来改变默认行为,Observable 应在该 Scheduler 上运行。另一方面,observeOn 方法指定了一个不同的 Scheduler,Observable 可以使用该 Scheduler 向观察者发送通知。
如前所述,Spring WebFlux 默认使用 Reactor 作为其 Reactive 库。但由于它与 Reactive Streams API 完全兼容,因此可以切换到另一种 Reactive Streams 实现,如 RxJava(适用于 RxJava 1.x 及其 Reactive Streams 适配器)。
添加依赖:
<dependency>
<groupId>io.reactivex.rxjava2</groupId>
<artifactId>rxjava</artifactId>
<version>2.2.21</version>
</dependency>
然后,在应用中使用 RxJava 类型(如 Observable)以及 RxJava 特定的 Scheduler:
io.reactivex.Observable
.fromIterable(Arrays.asList("Tom", "Sawyer"))
.map(s -> s.toUpperCase())
.observeOn(io.reactivex.schedulers.Schedulers.trampoline())
.doOnComplete(this::printThreads);
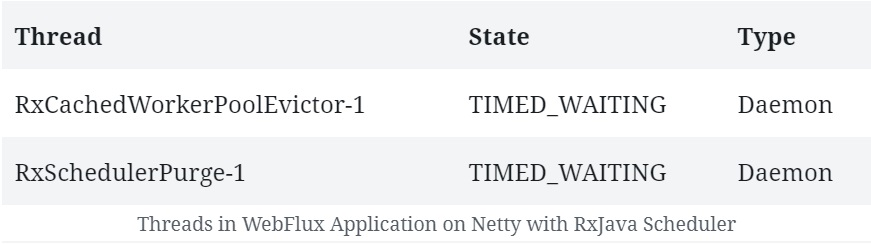
运行这个应用,除了常规的 Netty 和 JVM 相关线程外,还应该看到一些与 RxJava Scheduler 相关的线程:
10、总结
本文介绍了响应式和和传统编程模型之间的差异,还结合不同的 HTTP 运行时和 Reactive 库介绍了 WebFlux 中的线程模型。最后还介绍了在使用 WebClient 和数据访问库时,线程模型有何不同。
Ref:https://www.baeldung.com/spring-webflux-concurrency
