NVIDIA(英伟达)
| 本站(springdoc.cn)中的内容来源于 spring.io ,原始版权归属于 spring.io。由 springdoc.cn 进行翻译,整理。可供个人学习、研究,未经许可,不得进行任何转载、商用或与之相关的行为。 商标声明:Spring 是 Pivotal Software, Inc. 在美国以及其他国家的商标。 |
NVIDIA LLM API 是一个代理式 AI 推理引擎,提供来自 不同供应商 的多种模型。
Spring AI 通过复用现有的 OpenAI 客户端与 NVIDIA LLM API 集成。为此你需要将 base-url 设置为 integrate.api.nvidia.com,选择一个提供的 LLM 模型 并获取其 api-key。
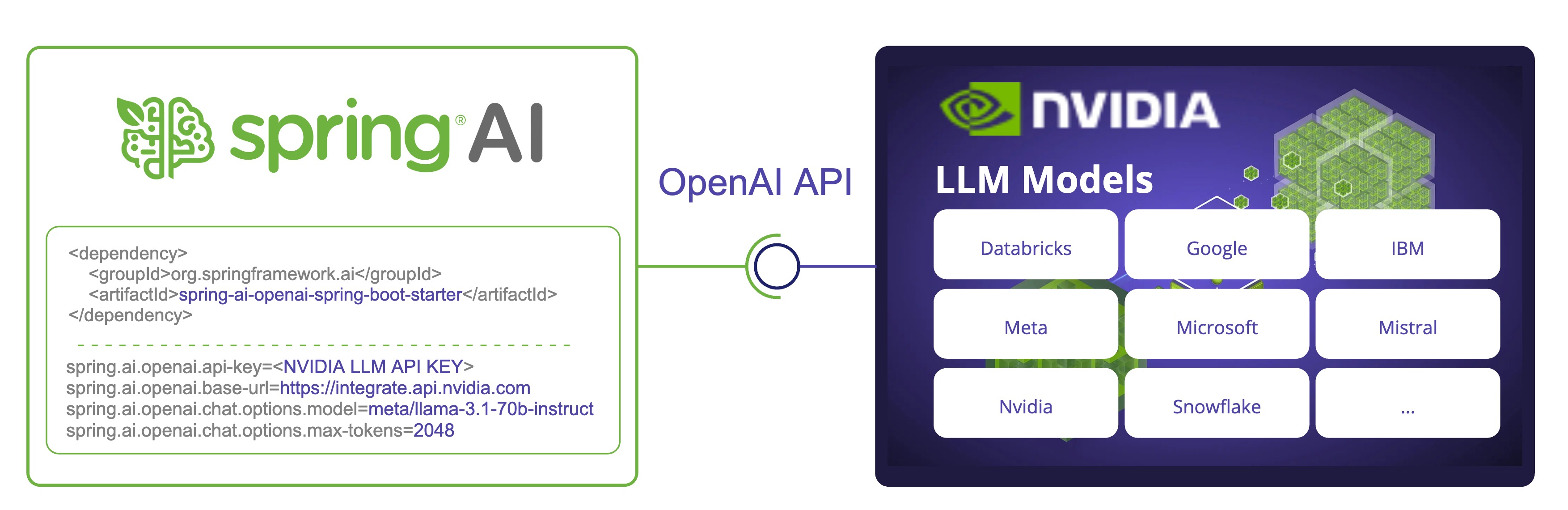
| 使用 NVIDIA LLM API 时必须显式设置 `max-token`s 参数,否则将抛出服务器错误。 |
查看 NvidiaWithOpenAiChatModelIT.java 测试示例,了解如何在 Spring AI 中使用 NVIDIA LLM API。
先决条件
-
创建具有充足额度的 NVIDIA 账户
-
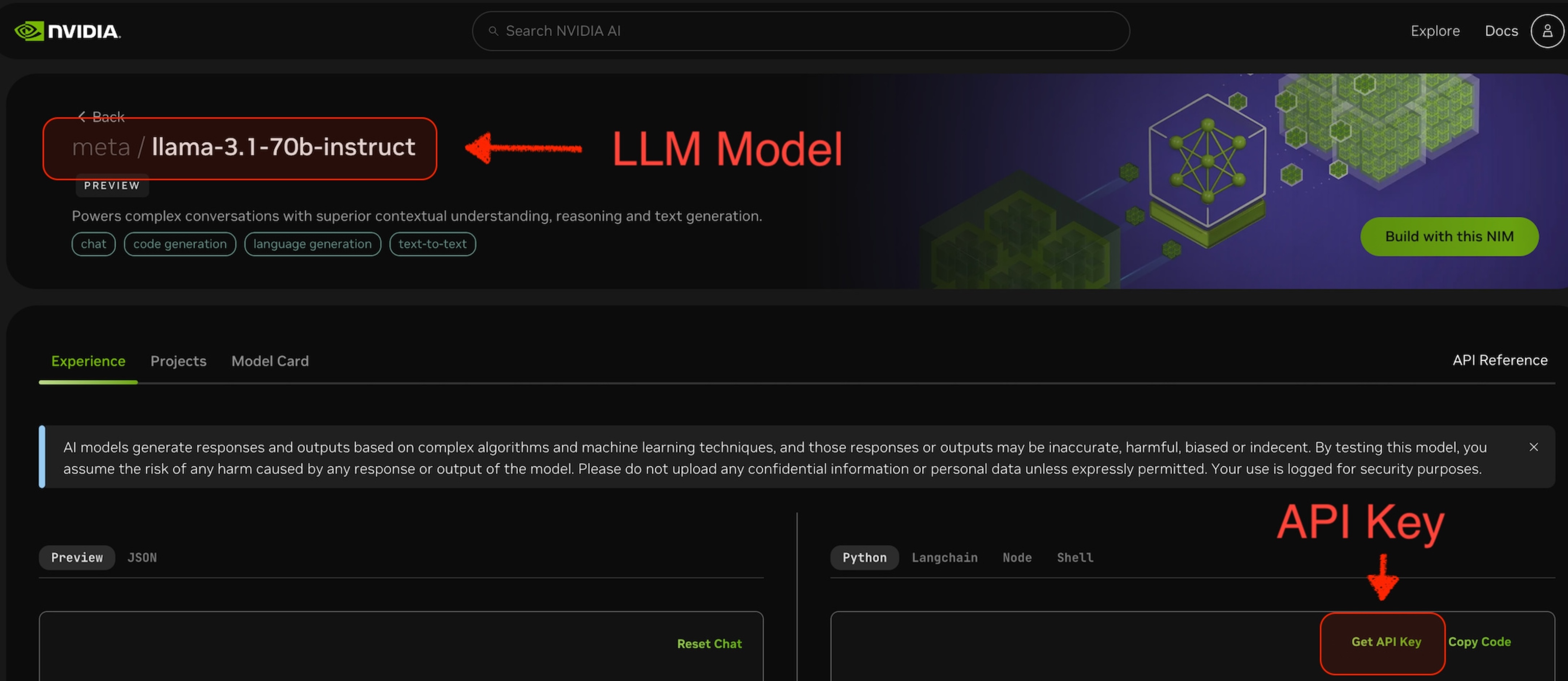
选择要使用的 LLM 模型。例如下图截屏中的
meta/llama-3.1-70b-instruct。 -
在所选模型的页面中,可获取访问该模型的
api-key。
自动配置
|
Spring AI 自动配置及 starter 模块的 artifactId 命名已发生重大变更。具体升级说明请参阅 更新文档。 |
Spring AI 为 OpenAI 聊天客户端提供 Spring Boot 自动配置。要启用该功能,请将以下依赖项添加到项目的 Maven pom.xml 文件中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>或添加到你的 Gradle build.gradle 构建文件中。
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}| 请参考 依赖管理 章节,将 Spring AI BOM 添加到构建文件中。 |
聊天配置
重试配置
前缀 spring.ai.retry 用作属性前缀,用于配置 OpenAI 聊天模型的重试机制。
| 属性 | 说明 | 默认值 |
|---|---|---|
spring.ai.retry.max-attempts |
最大重试次数。 |
10 |
spring.ai.retry.backoff.initial-interval |
指数退避策略的初始休眠时长。 |
2 sec. |
spring.ai.retry.backoff.multiplier |
退避间隔乘数。 |
5 |
spring.ai.retry.backoff.max-interval |
最大退避时长。 |
3 min. |
spring.ai.retry.on-client-errors |
若为 |
false |
spring.ai.retry.exclude-on-http-codes |
不应触发重试的 HTTP 状态码列表(例如用于抛出 |
empty |
spring.ai.retry.on-http-codes |
应触发重试的 HTTP 状态码列表(例如用于抛出 |
empty |
连接配置
前缀 spring.ai.openai 用作属性前缀,用于配置 OpenAI 连接参数。
| Property | Description | Default |
|---|---|---|
spring.ai.openai.base-url |
连接目标 URL。必须设置为 integrate.api.nvidia.com |
- |
spring.ai.openai.api-key |
NVIDIA API Key |
- |
配置属性
|
聊天自动配置的启用/禁用现在通过顶级属性配置,前缀为
此项变更是为了支持多模型配置。 |
前缀 spring.ai.openai.chat 用于配置 OpenAI 聊天模型实现的属性前缀。
| 属性 | 说明 | 默认值 |
|---|---|---|
spring.ai.openai.chat.enabled (已移除且不再有效) |
启用 OpenAI 聊天模型。 |
true |
spring.ai.model.chat |
启用 OpenAI 聊天模型。 |
openai |
spring.ai.openai.chat.base-url |
O可选参数,用于覆盖 |
- |
spring.ai.openai.chat.api-key |
可选参数,用于覆盖 |
- |
spring.ai.openai.chat.options.model |
要使用的 NVIDIA LLM 模型。 |
- |
spring.ai.openai.chat.options.temperature |
采样温度值参数,用于控制生成内容的表观创造性。较高值会使输出更随机,较低值则使结果更集中和确定。不建议在同一补全请求中同时修改 |
0.0f |
spring.ai.openai.chat.options.maxTokens |
聊天补全中生成的最大 Token 数。输入 Token 和生成 Token 的总长度受模型上下文长度限制。 |
注意:NVIDIA LLM API 要求必须显式设置 max-tokens 参数,否则将抛出服务器错误。 |
spring.ai.openai.chat.options.n |
为每条输入消息生成的聊天补全选项数量。请注意,系统将根据所有选项生成的 Token 总数计费。保持 n=1 可最大限度降低成本。 |
1 |
spring.ai.openai.chat.options.presencePenalty |
介于 -2.0 和 2.0 之间的数值。正值会根据新 Token 是否已出现在当前文本中进行惩罚,从而增加模型讨论新话题的可能性。 |
- |
spring.ai.openai.chat.options.responseFormat |
指定模型输出格式的对象。设置为 |
- |
spring.ai.openai.chat.options.seed |
该功能处于测试阶段。若指定此参数,系统将尽力进行确定性采样,使得使用相同种子和参数的重复请求应返回相同结果。 |
- |
spring.ai.openai.chat.options.stop |
最多可设置 4 个终止序列,当 API 生成到这些序列时将停止产生后续 Token。 |
- |
spring.ai.openai.chat.options.topP |
温度采样的替代方案——核采样(nucleus sampling),模型仅考虑概率质量累加达 top_p 值的 token 结果。例如 0.1 表示仅考虑概率质量排名前 10% 的 Token。通常建议仅修改此参数或温度参数,而非同时调整两者。 |
- |
spring.ai.openai.chat.options.tools |
模型可调用的工具列表。当前仅支持将函数作为工具使用。通过此参数提供函数列表,模型可能为其生成 JSON 格式的输入。 |
- |
spring.ai.openai.chat.options.toolChoice |
控制模型是否调用函数及调用方式:
|
- |
spring.ai.openai.chat.options.user |
表示终端用户的唯一标识符,可帮助 OpenAI 监控和检测滥用行为。 |
- |
spring.ai.openai.chat.options.functions |
函数名称列表,用于在单次提示请求中启用函数调用功能。这些名称对应的函数必须存在于 |
- |
spring.ai.openai.chat.options.stream-usage |
(仅限流式传输)设置后将为整个请求添加包含token使用统计信息的附加数据块。该数据块的 |
false |
spring.ai.openai.chat.options.proxy-tool-calls |
若为 |
false |
所有以 spring.ai.openai.chat.options 为前缀的属性,都可通过在 Prompt 调用中添加请求特定的 运行时选项 进行运行时覆盖。
|
运行时选项
OpenAiChatOptions.java 提供模型配置参数,包括使用的模型、温度值、频率惩罚系数等。
启动时,默认选项可通过 OpenAiChatModel(api, options) 构造函数或 spring.ai.openai.chat.options.* 属性进行配置。
运行时,你可以通过向 Prompt 调用添加新的请求特定选项来覆盖默认选项。例如,要针对特定请求覆盖默认模型和温度值:
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OpenAiChatOptions.builder()
.model("mixtral-8x7b-32768")
.temperature(0.4)
.build()
));| 除了特定于模型的 OpenAiChatOptions 外,你还可以使用可移植的 ChatOptions 实例(通过 ChatOptions#builder() 创建)。 |
函数调用
NVIDIA LLM API 在选择支持工具/函数调用的模型时,可启用该功能。
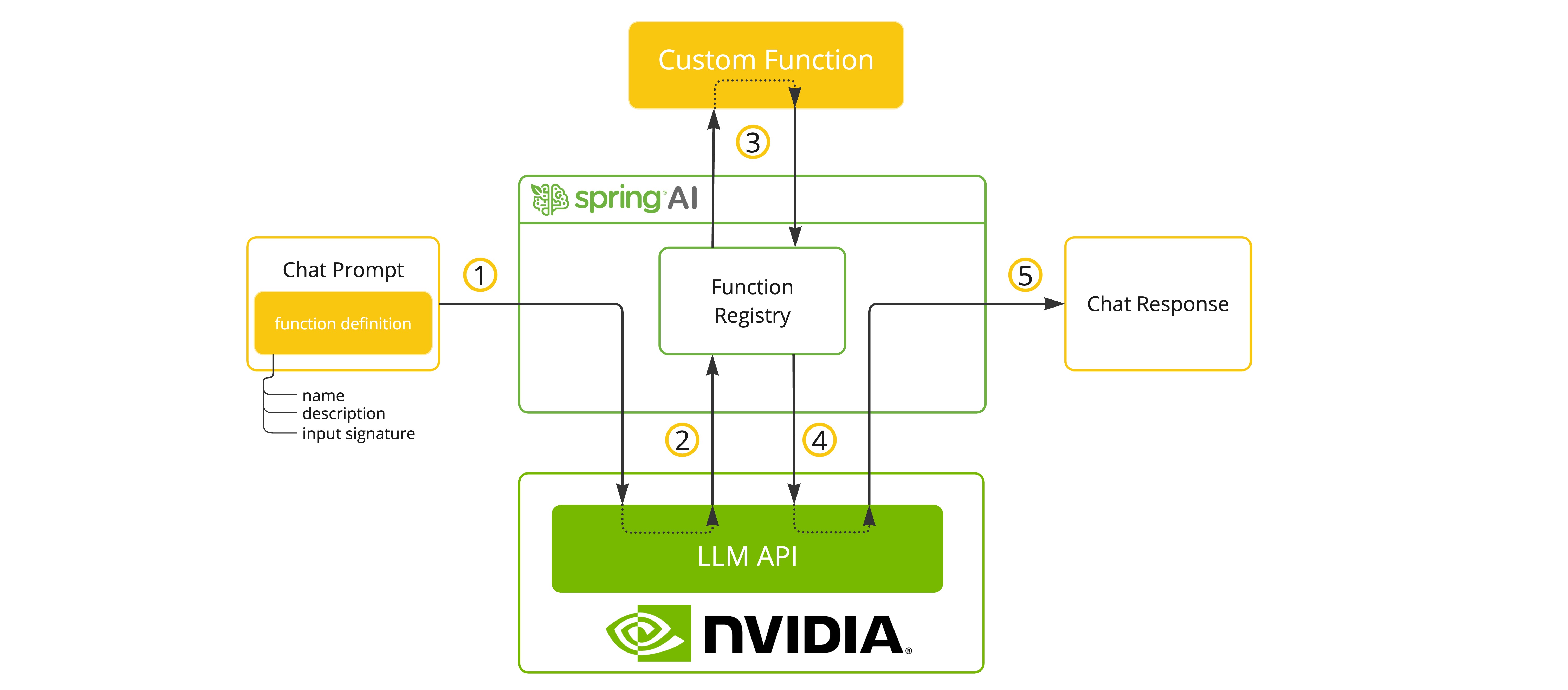
你可以为 ChatModel 注册自定义 Java 函数,使模型能智能选择输出包含参数的 JSON 对象来调用一个或多个已注册函数。这是将 LLM 能力与外部工具和 API 连接的强大技术。
工具示例
以下是使用 Spring AI 调用 NVIDIA LLM API 函数的简单示例:
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
spring.ai.openai.chat.options.max-tokens=2048@SpringBootApplication
public class NvidiaLlmApplication {
public static void main(String[] args) {
SpringApplication.run(NvidiaLlmApplication.class, args);
}
@Bean
CommandLineRunner runner(ChatClient.Builder chatClientBuilder) {
return args -> {
var chatClient = chatClientBuilder.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.functions("weatherFunction") // reference by bean name.
.call()
.content();
System.out.println(response);
};
}
@Bean
@Description("Get the weather in location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return new MockWeatherService();
}
public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> {
public record WeatherRequest(String location, String unit) {}
public record WeatherResponse(double temp, String unit) {}
@Override
public WeatherResponse apply(WeatherRequest request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new WeatherResponse(temperature, request.unit);
}
}
}本示例中,当模型需要天气信息时,将自动调用 weatherFunction Bean 获取实时天气数据。预期响应格式为:“The weather in Amsterdam is currently 20 degrees Celsius, and the weather in Paris is currently 25 degrees Celsius.”。
阅读更多关于 OpenAI 函数调用 的内容。
示例 Controller
新建 Spring Boot 项目并在 pom(或gradle)依赖中添加 spring-ai-starter-model-openai。
在 src/main/resources 目录下添加 application.properties 文件,用于启用和配置 OpenAi 聊天模型:
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings, so we need to disable it.
spring.ai.openai.embedding.enabled=false
# The NVIDIA LLM API requires this parameter to be set explicitly or server internal error will be thrown.
spring.ai.openai.chat.options.max-tokens=2048
将 api-key 替换为你的 NVIDIA 凭证。
|
NVIDIA LLM API 要求必须显式设置 max-token 参数,否则将抛出服务器错误。
|
以下是一个简单的 @Controller 类示例,演示如何使用该聊天模型进行文本生成:
@RestController
public class ChatController {
private final OpenAiChatModel chatModel;
@Autowired
public ChatController(OpenAiChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
