在 Spring Boot 中处理 Kafka Offset(偏移量)
本文将带你了解如何使用 Spring Boot 和 Spring Kafka 管理 Kafka 消费者偏移量(Offset)。
在之的一篇文章中,主要说明了应用处理 Kafka 消息的方式可能会影响系统的整体性能,并没有考虑消费者端的消息重复或消息丢失等问题。本文将会介绍这些话题。
1、源码
本文中的源码托管在 GitHub,你可以克隆它到本地,然后按照说明中的步骤操作即可。
2、简介
在开始之前,首先要说明一些与使用 Spring Kafka 提交偏移量有关的重要事项。首先,默认情况下,Spring Kafka 会将消费者的 enable.auto.commit 属性设置为 false。这意味着提交偏移量的责任在于框架,而非 Kafka。当然,我们可以通过将该属性设置为 true 来改变默认行为。顺便说一句,这也是 Spring Kafka 2.3 之前的默认做法。
禁用了 Kafka 自动提交(Auto Commit)后,我们就可以利用 Spring Kafka 提供的 7 种不同的提交策略。本文不会分析所有策略,只分析最重要的几种。默认策略是 BATCH。为了设置不同的策略,需要覆盖 AckMode,例如在 Spring Boot application.properties 中设置 spring.kafka.listener.ack-mode 属性的值。
首先来看看 BATCH 模式。
3、Spring Boot Kafka 应用示例
为了测试使用 Spring Kafka 进行的偏移提交,我们将创建两个简单的应用:producer (生产者)和 consumer(消费者)。生产者向 Topic 发送规定数量的消息,而消费者接收并处理这些消息。下面是生产者 @RestController 的实现。它允许我们按需向 transactions Topic 发送指定数量的消息:
@RestController
public class TransactionsController {
private static final Logger LOG = LoggerFactory
.getLogger(TransactionsController.class);
long id = 1;
long groupId = 1;
KafkaTemplate<Long, Order> kafkaTemplate;
@PostMapping("/transactions")
public void generateAndSendMessages(@RequestBody InputParameters inputParameters) {
for (long i = 0; i < inputParameters.getNumberOfMessages(); i++) {
Order o = new Order(id++, i+1, i+2, 1000, "NEW", groupId);
CompletableFuture<SendResult<Long, Order>> result =
kafkaTemplate.send("transactions", o.getId(), o);
result.whenComplete((sr, ex) ->
LOG.info("Sent({}): {}", sr.getProducerRecord().key(), sr.getProducerRecord().value()));
}
groupId++;
}
}
以下是生产者(producer)应用的配置属性。需要设置 Kafka Broker 的地址,以及 Key (Long)和 Value(JSON 格式)的序列化器类。
spring:
application.name: producer
kafka:
bootstrap-servers: ${KAFKA_URL}
producer:
key-serializer: org.apache.kafka.common.serialization.LongSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
如下所示,我们可以通过调用 POST /transactions 端点来发送消息:
$ curl -X 'POST' 'http://localhost:8080/transactions' \
-H 'Content-Type: application/json' \
-d '{"numberOfMessages":10}'
下面是消费者(consumer)应用 Listener Bean 的实现。如你所见,它非常简单。它只是接收并打印消息。我们让线程休眠 10 秒,只是为了在测试过程中能方便检查 Kafka Topic 的偏移量。
@Service
public class Listener {
private static final Logger LOG = LoggerFactory
.getLogger(NoTransactionsListener.class);
@KafkaListener(
id = "transactions",
topics = "transactions",
groupId = "a"
)
public void listen(@Payload Order order,
@Header(KafkaHeaders.OFFSET) Long offset,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition) throws InterruptedException {
LOG.info("[partition={},offset={}] Starting: {}", partition, offset, order);
Thread.sleep(10000L);
LOG.info("[partition={},offset={}] Finished: {}", partition, offset, order);
}
}
为了查看消费者应用中发生的具体情况,需要将 Spring Kafka 的默认日志级别提高到 DEBUG。下面是消费者应用的完整 application.yml 文件,其中还有一些与消息序列化和反序列化相关的其他属性:
consumer/application.yml
spring:
application.name: consumer
output.ansi.enabled: ALWAYS
kafka:
bootstrap-servers: ${KAFKA_URL:localhost}:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.LongDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring.json.trusted.packages: "*"
logging.level:
org.springframework.kafka: debug
4、理解 Spring Kafka 如何提交偏移量的
然后,执行下面的 Maven 命令,启动两个应用。假设你已经运行了 Kafka Broker。一旦消费者连接到 transactions Topic,我们就可以通过调用前面提到的 POST /transactions 端点发送 10 条消息。之后,切换消费者应用日志。可以看到与偏移提交相关的所有重要信息。
# 构建整个项目
$ mvn clean package
# 运行消费者应用
$ cd consumer
$ mvn spring-boot:run
# 运行生产者应用
$ cd producer
$ mvn spring-boot:run
测试日志如下。最重要的部分已经标识出来了。当然,你的结果可能会略有不同,但规则是一样的。首先,消费者接收到一批消息。在这种情况下,有 2 条消息,但例如,在下一个分区中,它一次性消费了 7 条消息。如果没有详细的日志,你甚至不会意识到它的行为,因为消息监听器在处理一条消息后才会处理另一条消息。然而,偏移提交操作是在处理所有已消费消息之后执行的。这是因为我们将 AckMode 设置为了 BATCH 模式。
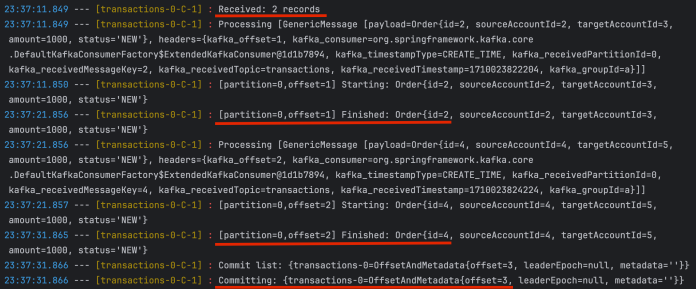
当然,在应用运行期间,这对应用没有任何影响。但是,如果在开始处理批量消息和偏移提交操作之间发生非优雅的重启或崩溃,可能会导致一些问题。这是一种很常见的情况,会导致消费者端出现重复的消息。
现在我们的应用在批处理中消费了 7 条消息。让我们在批量处理过程中停止它,如下所示,为了测试目的,使用 SIGKILL 选项强制结束进程。
使用优雅关闭的话(
kill -15),Spring Kafka 会等待批处理中的最后一条消息被处理完毕。
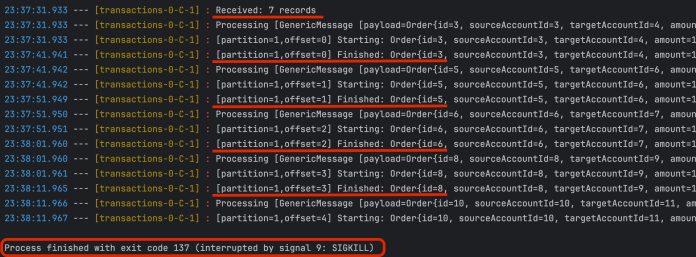
消费者偏移尚未提交。我们可以通过查看 分区 1 上消费者偏移量的当前值来验证。可以将该值与上述日志中突出显示的值进行比较。

然后,再次启动消费者应用。应用开始从每个分区最新提交的偏移量读取消息。因此,在杀死消费者实例之前,它会处理之前已经处理过的几条消息。如你所见,消费者应用再次处理 ID 为 3、5、6、8 和 10 的订单。我们需要在业务逻辑实现过程中考虑到这种情况。批量处理完最后一条消息后,Spring Kafka 会提交偏移量。
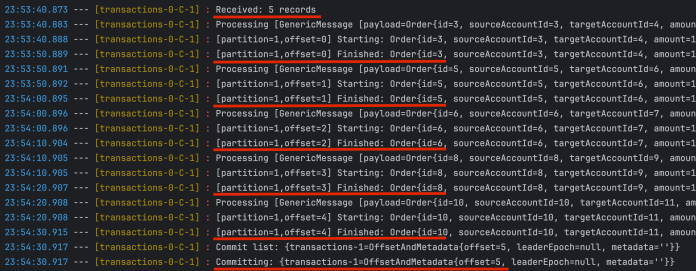
最后,一切正常。任何分区都没有出现消费者滞后现象。

5、使用 RECORD 模式提交偏移量
接下来,看看把 AckMode 设置为 RECORD 时的类似情况。根据 Spring Kafka 文档,RECORD 模式 “在监听器处理完记录(RECORD)返回时提交偏移量”。
在 application.yml 文件中设置以下内容,启用 RECORD 模式:
spring.kafka.listener.ack-mode: RECORD
然后,必须重新启动消费者应用。之后,可以通过调用生产者应用暴露的 POST /transactions 端点,再次发送消息:
$ curl -X 'POST' 'http://localhost:8080/transactions' \
-H 'Content-Type: application/json' \
-d '{\"numberOfMessages\":10}'
切换到日志。如你所见,每次使用 @KafkaListener 方法处理完一条记录后,Spring Kafka 都会提交偏移量。很多人认为这是默认行为(而不是 BATCH 模式)。这种方法减少了重启后可能出现的重复消息数量,但影响了消费者的整体性能(每次消费一条消息后都要提交偏移量)。
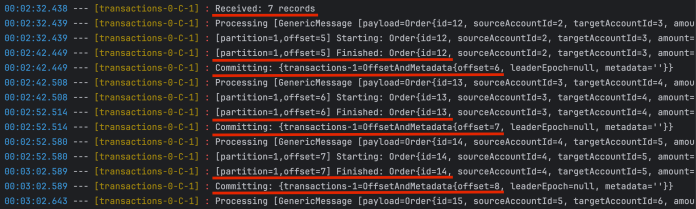
日志中显示的最消费者偏移量是 8。因此,如果我们切换到图形用户界面客户端,就可以验证当前偏移量的值是否相同。

6、优雅停机
虽然我们的应用每次在处理完一条记录后都会提交偏移量,但在优雅停机时,Spring Boot 会等到整个批处理完成。如下所示,我在 15:12:41 关闭了应用,但容器在超时 30 秒后执行了关闭。这是因为我在处理方法中加入了 10 秒的线程休眠。这导致处理这批消息的总时间超过了 30 秒。
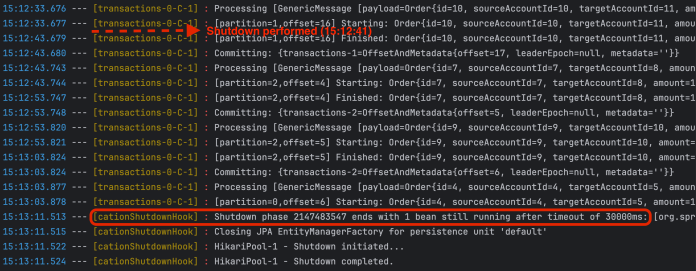
也可以改变这种行为,将 spring.kafka.listener.immediate-stop 属性设置为 true。该属性决定容器是在处理完当前消息后停止,还是在处理完上一次轮询的所有消息后停止。
spring.kafka.listener.immediate-stop: true
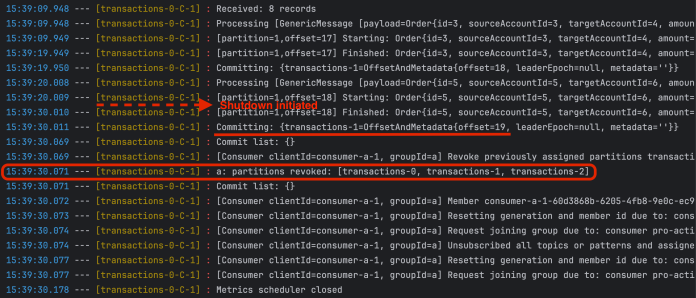
重启消费者应用后,再次查看日志。Spring 容器在处理完最后一条记录并提交偏移量后立即启关闭。
7、Spring Kafka 偏移量和并发处理的问题
7.1、使用自定义线程池处理消息
接下来看看使用自定义线程来处理 @KafkaListener 方法接收到的消息的情况。为此,我们可以定义 ExecutorService 对象。一旦 listenAsync() 方法接收到消息,它就会使用 ExecutorService 对象调用 ProcessorBean 的 process() 方法,将处理工作委托给 ProcessorBean。
@Service
public class Listener {
private static final Logger LOG = LoggerFactory
.getLogger(Listener.class);
ExecutorService executorService = Executors.newFixedThreadPool(30);
@Autowired
private Processor processor;
@KafkaListener(
id = "transactions-async",
topics = "transactions-async",
groupId = "a"
)
public void listenAsync(@Payload Order order,
@Header(KafkaHeaders.OFFSET) Long offset,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition) {
LOG.info("[partition={},offset={}] Starting Async: {}", partition, offset, order);
executorService.submit(() -> processor.process(order));
}
}
在 Processor Bean 中,为了测试目的,我们让线程休眠 10 秒。process() 方法只是在开始和结束前打印日志。
@Service
public class Processor {
private static final Logger LOG = LoggerFactory
.getLogger(Listener.class);
public void process(Order order) {
LOG.info("Processing: {}", order.getId());
try {
Thread.sleep(10000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
LOG.info("Finished: {}", order.getId());
}
}
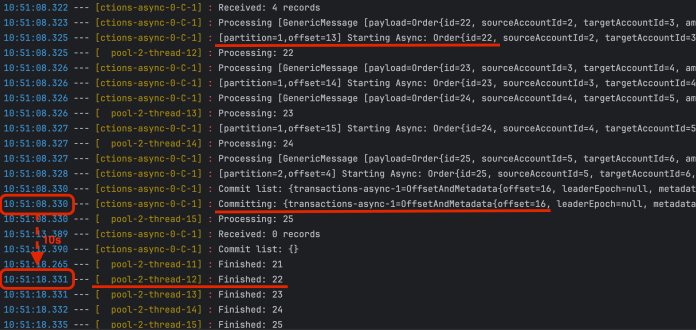
这次我们使用了 transaction-async Topic。默认情况下,Spring Kafka 在处理完整个批处理的 4 条接消息之后提交偏移量。然而,由于我们将进一步的处理委派给另一个线程,所以几乎立即在接收到消息后就会进行提交。异步方法在 10 秒后完成处理。如果在这 10 秒内应用崩溃,将导致消息丢失。它们不会被其他实例(消费者)处理,因为在消息处理完成之前偏移量已经被提交。
7.2、手动提交偏移量
再次强调,Kafka 消费者消息可能会丢失,这是正常情况。不过,我们可以用稍微不同的方式来处理这种情况。可以切换到手动模式,而不是依赖容器来管理偏移量。首先,在 Spring Boot application.yml 文件中添加以下属性:
spring.kafka.listener.ack-mode: MANUAL_IMMEDIATE
然后,我们需要利用 Acknowledgment 接口在监听器内部控制偏移量提交过程。如你所见,必须在 @KafkaListener 方法参数中包含该接口。之后,就可以将它传递给在不同线程中运行的 process() 方法。
@Service
public class Listener {
private static final Logger LOG = LoggerFactory
.getLogger(Listener.class);
ExecutorService executorService = Executors.newFixedThreadPool(30);
@Autowired
private Processor processor;
@KafkaListener(
id = "transactions-async",
topics = "transactions-async",
groupId = "a"
)
public void listenAsync(@Payload Order order,
Acknowledgment acknowledgment,
@Header(KafkaHeaders.OFFSET) Long offset,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition) {
LOG.info("[partition={},offset={}] Starting Async: {}", partition, offset, order);
executorService.submit(() -> processor.process(order, acknowledgment));
}
}
通过 Acknowledgment 接口提供的 acknowledge() 方法,我们可以在代码中指定的位置手动提交偏移量。如下,在方法的最后进行提交。
@Service
public class Processor {
private static final Logger LOG = LoggerFactory
.getLogger(Listener.class);
public void process(Order order, Acknowledgment acknowledgment) {
LOG.info("Processing: {}", order.getId());
try {
Thread.sleep(10000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
LOG.info("Finished: {}", order.getId());
acknowledgment.acknowledge();
}
}
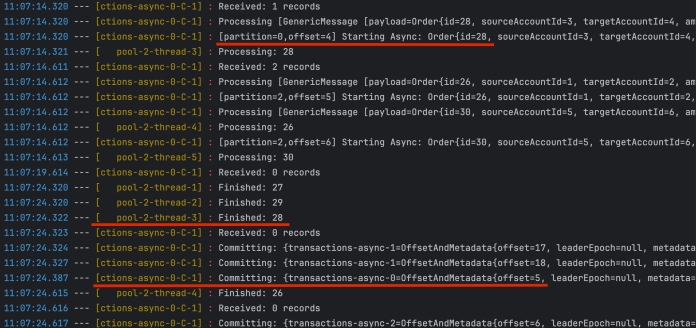
再次切换到消费者应用日志。偏移提交几乎是在处理消息后立即发生的。顺便说一下,使用 MANUAL(不是 MANUAL_IMMEDIATE) AckMode 将等待整个批处理记录被处理后再进行提交。还有一点值得一提,那就是可能会出现无序提交的情况。Spring Boot 应用默认禁用该功能。要启用它,需要将 spring.kafka.listener.async-acks 属性设置为 true。如果你想自己测试这种情况,可以使用 numberOfMessages 字段增加生产者发送的消息数量,例如增加到 100。然后,使用或不使用 asyncAcks 属性来验证消费者滞后情况。
最后,使用 GUI 客户端来验证所有分区的当前已提交偏移量。

8、最后
Kafka 消费者偏移是一个非常有趣的话题。如果你想了解 Kafka,首先需要了解消费者如何在分区上提交偏移量。本文重点介绍了如何使用 Spring Kafka 在不同的确认模式(AckMode)之间切换,以及这对应用有何影响。
Ref:https://piotrminkowski.com/2024/03/11/kafka-offset-with-spring-boot/
