使用 Spring AI 和 Redis 构建快速、可用于生产环境的 AI 应用
本文由 Broadcom 的 Spring 开发者倡导者 Josh Long 和 Redis 的应用 AI 工程师 Brian Sam-Bodden 共同撰写,旨在展示如何在 Spring AI 1.0 中使用 Redis。
Spring AI 1.0 是面向 Java 开发的综合性 AI 工程解决方案。受 AI 领域飞速发展的影响,该版本经过了一个重要的开发阶段,现已发布。该版本为 AI 工程师提供了多项核心新功能。Redis 作为 Spring AI 的原生向量数据库,可助力构建高性能 AI 应用。
当前 Java 和 Spring 正处于 AI 应用的黄金时期。大量企业应用基于 Spring Boot 运行,这使其能轻松将 AI 能力集成至现有系统。你可直接将业务逻辑和数据无缝对接 AI 模型,无需复杂改造。
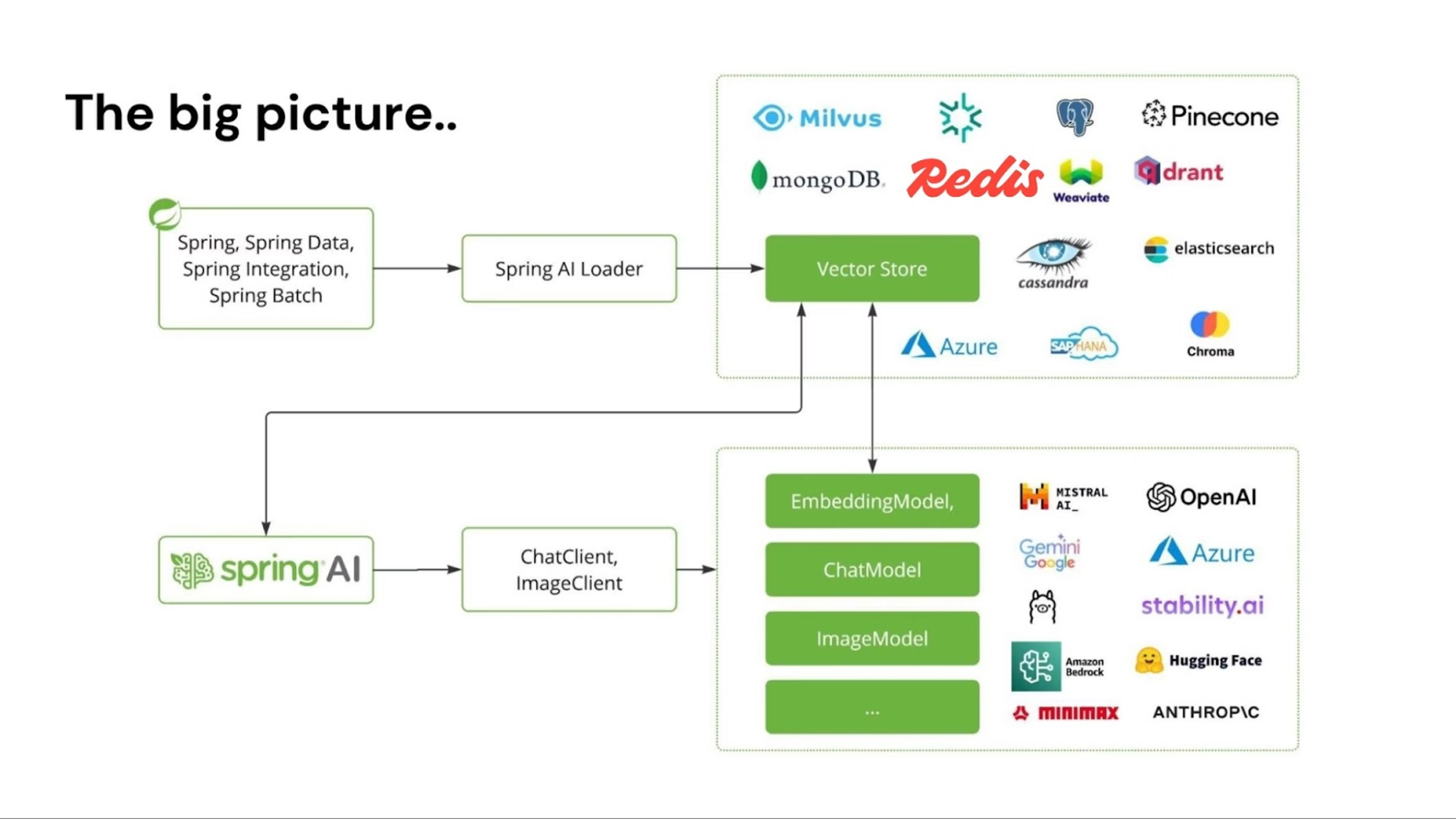
Spring AI 支持多种 AI 模型与技术:
- Image model(图像模型):根据文本提示生成图像。
- Transcription model(转录模型):将音频转换为文本。
- Embedding model(嵌入模型):将任意数据转换为向量(专为语义相似性搜索优化的数据类型)。
- Chat model(对话模型):用户最熟悉的类型,可辅助文档修正或诗歌创作(但暂不建议用于讲笑话),虽功能强大但仍存在局限。
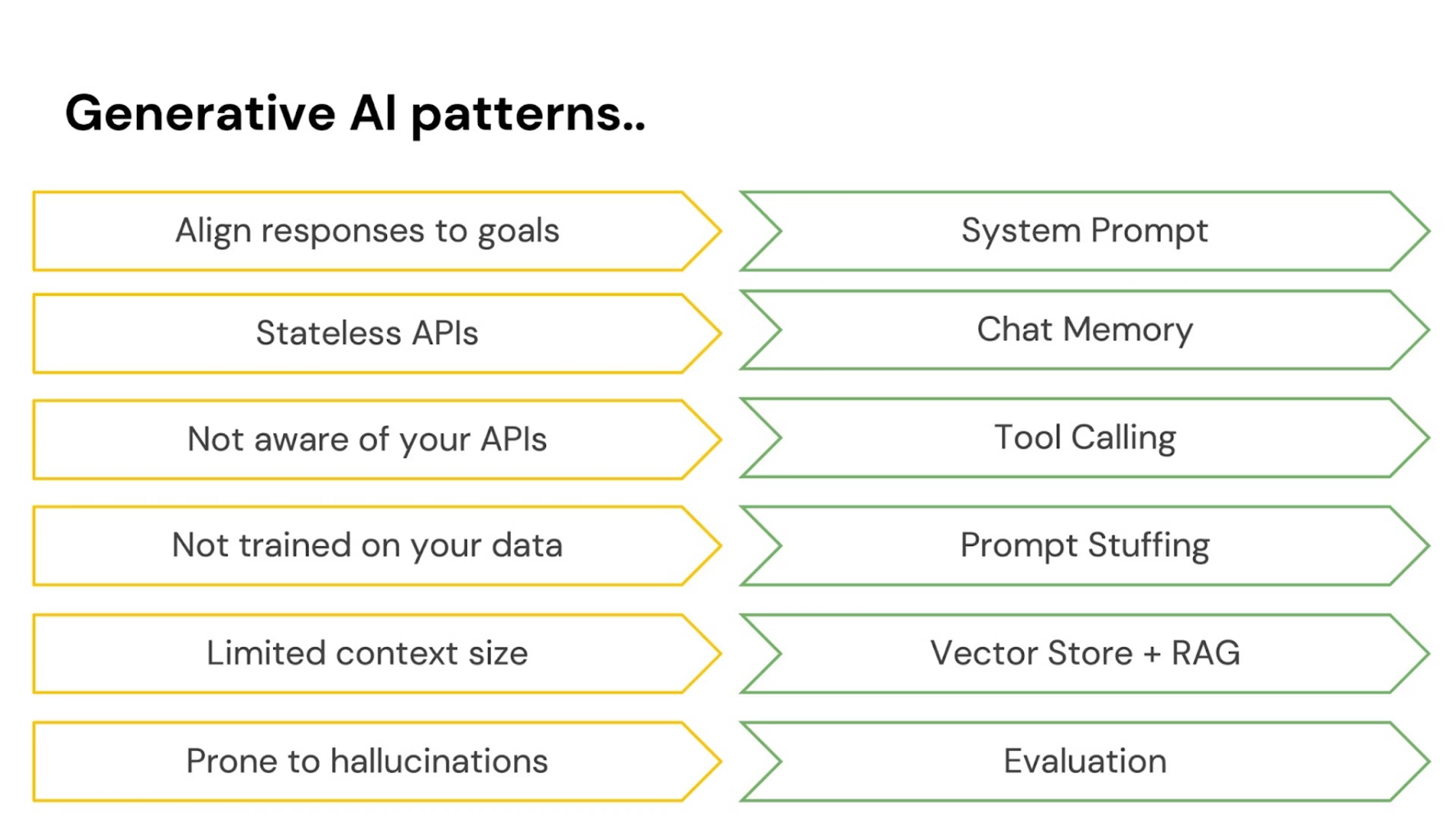
在 Spring AI 中,需要解决一些问题:对话模型具有开放性思维,容易偏离主题,需要通过 system prompt(系统提示)来规范其响应结构和形式。
AI 模型不具备记忆功能,需借助 memory(记忆机制)来实现用户消息间的关联。
AI 模型运行在隔离沙箱中,但通过 tools(可自主调用的函数)能实现更强大功能。Spring AI 支持 tool calling,可向 AI 声明环境中的工具,由其自主请求调用,整个过程实现透明的多轮交互。
此外,AI 模型虽智能但非全能:无法获知专有数据库内容(通常也不应获知)。需通过 augmenting the prompts(本质是利用字符串拼接在请求中添加背景文本)引导其响应,这些内容会在处理用户问题前被模型考量。
最后,虽然可以通过大量数据增强模型能力,但数据量并非无限。解决方案是使用 vector store(向量数据库)筛选仅相关数据传入,该技术称为 retrieval augmented generation(RAG)。
AI 对话模型存在虚构内容的风险,需通过 evaluation(用一个模型校验另一个模型的输出)确保结果可靠性。
现代 AI 系统需与其他服务集成才能发挥最大价值。Model Context Protocol (MCP) 可实现跨语言的 AI 应用与 MCP 服务的连接,最终可组装成 agentic 工作流以实现更宏观目标。
你可以在熟悉的 Spring Boot 开发范式上实现所有这些功能:
- Spring Initializr 提供各类便捷的 starter 依赖。
- Spring AI 提供开箱即用的 Spring Boot 自动配置,遵循约定优于配置原则。
- 支持通过 Spring Boot Actuator 和 Micrometer 项目实现可观测性。
- 完美兼容 GraalVM 和虚拟线程,可构建高性能、可扩展的 AI 应用。
RAG 应代表 “Redis Augmented Generation”
你可能已安装 Redis,并深知其卓越性能。你或许早已了解它在键值存储领域的顶尖地位。
但你是否知道:
- 支持会话(session)存储,具备键过期功能和多节点分布式存储能力。
- 通过 Redlock 等特性实现分布式环境下的互斥锁管理。
- 支持功能开关和配置管理,提供高速读写及 TTL 特性。
- 借助 STREAMS 实现实时事件日志存储与流处理。
- 使用有序集合(ZSET)结构处理排行榜等排序场景。
- 通过 LIST、STREAM 和 PUBSUB 实现消息队列与发布订阅。
- 基于 ZSET 或 TRIE 结构实现搜索与自动补全。
- 利用原子计数器支持实时分析与计数。
Redis 在保持全球最快数据库性能的同时,完美支持向量存储。RAG 是现代 AI 应用的核心组件——虽然当前模型支持每次请求发送海量数据,但这种方式效率低下且成本高昂。实际解决方案是精准发送最相关数据,而 Redis 凭借其持久性和高速特性,能极速判定数据相关性。
来看一个简单应用。
访问 Spring Initializr 创建应用,指定 Redis vector database、Docker compose、OpenAI、GraalVM、Actuator 和 Web 依赖。使用 Java 24 和 Apache Maven 作为构建工具。点击 Generate 后获得一个 zip 文件,解压后得到可导入任意 IDE 的项目。
首先,需要连接 Redis 数据库。Spring Initializr 生成的项目包含有效的 compose.yml,可提供功能完整的 Redis 实例,Spring Boot 会在每次启动应用时自动启停该 Redis 实例。为避免每次重启实例,我们通过在 application.properties 中添加配置,让 Spring Boot Docker Compose 支持仅在实例未运行时启动它。
spring.docker.compose.lifecycle-management=start_only
生成的 compose.yml 已包含主要配置,但在开发过程中,在进行数据修改时登录 Redis 实例检查数据非常有用。
推荐使用 redis-cli 进行命令行访问,或使用极其直观的 Redis Insight 可视化工具(可通过 Homebrew 安装:brew install –cask redis-insight)。
我们要构建一个关于啤酒世界的应用,这需要在 Redis 中初始化一些数据。
spring.ai.vectorstore.redis.initialize-schema=true
spring.ai.vectorstore.redis.index-name=beers
spring.ai.vectorstore.redis.prefix=beer:
现在构建我们的 RAG 应用。目标是让用户能查询啤酒推荐搭配方案。具体数据源来自示例代码中 26MB 的 gzip 压缩文件 beers.json.gz。我们将通过 Spring AI 的 JsonReader 和基础 I/O 操作,在应用启动时通过 ApplicationRunner Bean 将这些数据加载到向量数据库。
private static final Resource BEERS_DATA = new ClassPathResource("/beers.json.gz");
@Bean
ApplicationRunner vectorStoreInitializer(
RedisVectorStoreProperties properties,
RedisVectorStore vectorStore) {
return _ -> {
var indexInfo = vectorStore.getJedis().ftInfo(properties.getIndexName());
var numDocs = (Long) indexInfo.getOrDefault("num_docs", 0L);
if (numDocs != 0)
return;
System.out.println("Creating Embeddings... (this may take a while)");
try (var inputStream = new GZIPInputStream(BEERS_DATA.getInputStream())) {
var resource = new InputStreamResource(inputStream, "beers.json.gz");
var loader = new JsonReader(resource, "name,abv,ibu,description".split(","));
vectorStore.add(loader.get());
System.out.println("Embeddings created!");
}
};
}
运行此操作并等待(可能需要数分钟完成)。
可通过 redis-cli 检查数据:
~ redis-cli
127.0.0.1:6379> ft._list
1) beers
也可查看索引详细信息:
127.0.0.1:6379> ft.info beers
1) index_name
2) beers
3) index_options
4) (empty array)
5) index_definition
6) 1) key_type
2) JSON
3) prefixes
4) 1) beer:
5) default_score
6) "1"
7) attributes
8) 1) 1) identifier
2) $.content
3) attribute
4) content
....
不过我更偏爱通过 Redis Insight 直接查看数据本身。
啤酒品类繁多,选择困难。为此我们将构建智能助手,结合 Spring AI 和 Redis 向量存储数据,帮助用户做出明智选择。
现在通过 Spring MVC Controller 实现该啤酒助手:
@Controller
@ResponseBody
class BeerController {
private final ChatClient ai;
BeerController(ChatClient.Builder ai, VectorStore vectorStore) {
var defaultSystemPrompt = """
You're assisting with questions about products in a beer catalog.
Use the information from the DOCUMENTS section to provide accurate answers.
The answer involves referring to the ABV or IBU of the beer, include the beer name in the response.
If unsure, simply state that you don't know.
""";
this.ai = ai
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore))
.defaultSystem(defaultSystemPrompt)
.build();
}
@GetMapping("/beers")
String beers(@RequestParam String question) {
return this.ai
.prompt()
.user(question)
.call()
.content();
}
}
该 Controller 公开一个 /beers 端点用于接收问题请求。在 Controller 构造函数中,通过以下步骤配置 Spring AI ChatClient:
- 首先定义 system prompt(系统提示词),用于控制模型响应的整体风格。
- 由于模型需要感知 Redis 向量存储中的数据,我们通过
QuestionAnswerAdvisor(需添加对应依赖)配置 advisor(可预处理和后处理模型请求的拦截器)。
依赖配置示例:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
至此配置完成。运行程序后,可按以下方式访问端点:
http :8080/beers question=="what beer pairs best with meats?"
响应类似如下:
HTTP/1.1 200
Connection: keep-alive
Content-Length: 215
Content-Type: text/plain;charset=UTF-8
Date: Sat, 03 May 2025 20:07:42 GMT
Keep-Alive: timeout=60
For pairing with meats, I recommend the Swabian Hall, which has an ABV of 4.7 and an IBU of 30. It's a Smoked Brown Ale that's perfect for hog roasts, making it an excellent choice to complement various meat dishes.
生产级 AI
现在,需要将目光转向生产环境部署。
可扩展性
我们需要确保代码具备可扩展性。需注意:每次向 LLM(或多数 SQL 数据库)发起 HTTP 请求时,都会产生阻塞式 I/O 操作——线程被占用且无法处理其他任务,直到 I/O 完成。这种线程空转是资源浪费。
Java 21 及以上版本提供的虚拟线程,能显著提升 I/O 密集型服务的扩展性。因此我们在 application.properties 中配置了 spring.threads.virtual.enabled=true。
GraalVM 原生镜像
GraalVM 作为生产级编译器,可通过 GraalVM Community Edition 开源项目或功能更强大的 Oracle GraalVM 发行版(免费)使用。
GraalVM 要求明确声明应用中的动态行为,包括 JNI 代理、资源加载、序列化、反射等。由于当前使用的 Java Redis 驱动会在运行时加载部分组件,需在 main 类中添加以下配置:
static class Hints implements RuntimeHintsRegistrar {
@Override
public void registerHints(RuntimeHints hints, ClassLoader classLoader) {
hints.resources().registerPattern("redis/clients/jedis/pom.properties");
hints.resources().registerPattern("redis/clients/jedis/LICENSE");
hints.resources().registerResource(BEERS_DATA);
}
}
若已配置上述 SDK 环境,可轻松将该 Spring AI 应用转换为特定操作系统和架构的原生镜像:
./mvnw -DskipTests -Pnative native:compile
在多数机器上此过程需约一分钟,完成后即可直接运行生成的二进制文件。
./target/redis
该程序的启动时间将远短于 JVM 运行时的启动耗时。你可能需要注释掉之前创建的 ApplicationRunner,因其会在启动时执行 I/O 操作显著延迟启动。实测显示,启动时间可缩短至 0.1 秒以内。
更显著的优势在于内存占用——相比 JVM 运行环境,该应用仅需极小部分内存。
你可能仍需将其部署至云平台,这意味着需打包为 Docker 镜像。实现非常简单。
./mvnw -DskipTests -Pnative spring-boot:build-image
请稍候,此过程可能仍需约一分钟。完成后将输出生成的 Docker 镜像名称。
运行时可覆盖原主机配置的 hosts 和 ports 参数。
docker run docker.io/library/redis:0.0.1-SNAPSHOT
我们在 macOS 系统上测试发现:该应用在模拟 Linux 的 macOS 虚拟机中运行时,启动速度和执行效率甚至比原生 macOS 环境更优。
可观测性
务必监控系统资源及关键指标 Token 计数。所有 LLM 请求都会产生成本——至少是复杂度成本,甚至直接经济成本。幸运的是,Spring AI 提供内置支持:发起若干模型请求后,可访问 Spring Boot Actuator 的 metrics 端点(基于 Micrometer.io):
http://localhost:8080/actuator/metrics
此时可查看与 Token 消耗相关的指标数据。你可通过 Micrometer 将这些指标转发至任意时序数据库,实现统一监控仪表盘。
接下来
你已快速构建了一个具备生产就绪能力的、基于 Spring AI 和 Redis 数据库的 AI 应用。目前我们仅触及了表面功能,还可进一步:
- 添加对话记忆功能。
- 利用 Spring AI 的 Model Context Protocol (MCP) 支持(Spring AI 团队开发了 Java MCP SDK,该 SDK 是其他所有 MCP 集成的基础)将啤酒功能导出为 MCP 服务。
- 集成静态数据加密安全方案。
更多可能性等待探索。现在即可通过 Spring Initializr 体验 Spring AI 1.0,并 深入了解 Redis。
Ref:https://redis.io/blog/build-fast-production-worthy-ai-apps-with-spring-ai-and-redis/
