配置和运行一个 Job
| 本站( springdoc.cn )中的内容来源于 spring.io ,原始版权归属于 spring.io。由 springdoc.cn 进行翻译,整理。可供个人学习、研究,未经许可,不得进行任何转载、商用或与之相关的行为。 商标声明:Spring 是 Pivotal Software, Inc. 在美国以及其他国家的商标。 |
在 领域(domain)部分,以下列图表为指导,讨论了整体的架构设计:
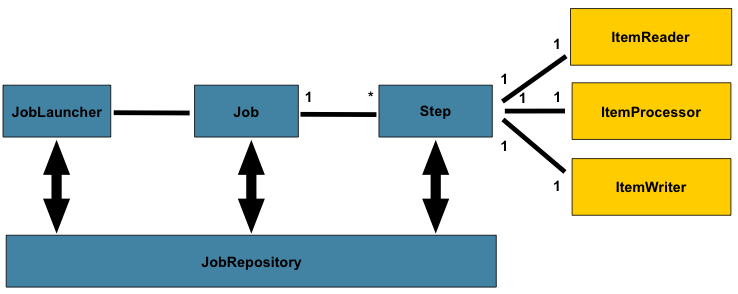
虽然 Job 对象看起来是一个简单的 step 容器,但你必须了解许多配置选项。此外,你必须考虑许多关于如何运行 Job 以及在运行期间如何存储其元数据的选项。本章解释了 Job 的各种配置选项和运行时的注意事项。
配置 Job
There are multiple implementations of the Job interface. However,
builders abstract away the difference in configuration.
The following example creates a footballJob:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
A Job (and, typically, any Step within it) requires a JobRepository. The
configuration of the JobRepository is handled through the Java Configuration.
The preceding example illustrates a Job that consists of three Step instances. The job related
builders can also contain other elements that help with parallelization (Split),
declarative flow control (Decision), and externalization of flow definitions (Flow).
There are multiple implementations of the Job
interface. However, the namespace abstracts away the differences in configuration. It has
only three required dependencies: a name, JobRepository , and a list of Step instances.
The following example creates a footballJob:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>The examples here use a parent bean definition to create the steps.
See the section on step configuration
for more options when declaring specific step details inline. The XML namespace
defaults to referencing a repository with an ID of jobRepository, which
is a sensible default. However, you can explicitly override it:
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>In addition to steps, a job configuration can contain other elements that help with
parallelization (<split>), declarative flow control (<decision>) and externalization
of flow definitions (<flow/>).
重新启动的能力
执行批处理 job 时的一个关键问题涉及到 Job 重新启动时的行为。如果一个 JobExecution 已经存在于特定的 JobInstance 中,那么 Job 的启动就被认为是 "重新启动" 了。理想情况下,所有的 job 都应该能够从它们离开的地方启动,但在某些情况下这是不可能的。在这种情况下,完全由开发者来确保创建一个新的 JobInstance。然而,Spring Batch 确实提供了一些帮助。如果一个 Job 不应该被重新启动,而应该总是作为新的 JobInstance 的一部分来运行,你可以将 restartable 属性设置为 false。
下面的例子显示了如何在XML中把 restartable 字段设置为 false:
<job id="footballJob" restartable="false">
...
</job>下面的例子显示了如何在 Java 中把 restartable 字段设置为 false:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.preventRestart()
...
.build();
}
换一种说法,将 restartable 设置为 false 意味着 "此 Job 不支持再次启动"。重启一个不可重启的 Job 会导致抛出一个 JobRestartException。下面的Junit代码会导致该异常被抛出:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}
第一次尝试为一个不可重启的 job 创建 JobExecution,没有引起任何问题。然而,第二次尝试会抛出一个 JobRestartException。
拦截 Job 的执行
在一个 Job 的执行过程中,在其生命周期中被通知各种事件可能是有用的,这样就可以运行自定义代码。 SimpleJob 通过在适当的时候调用 JobListener 来实现这一点:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
你可以通过在 job 上设置 listener 来向 SimpleJob 添加 JobListeners。
下面的例子显示了如何在 XML job 定义中添加一个 listener 元素:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>下面的例子显示了如何在 Java job 定义中添加一个 listener 方法:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.listener(sampleListener())
...
.build();
}
请注意,无论 Job 的成功或失败,都会调用 afterJob 方法。如果你需要确定成功或失败,你可以从 JobExecution 中获得这些信息:
public void afterJob(JobExecution jobExecution){
if (jobExecution.getStatus() == BatchStatus.COMPLETED ) {
//job success
}
else if (jobExecution.getStatus() == BatchStatus.FAILED) {
//job failure
}
}
与该接口相对应的注解是:
-
@BeforeJob -
@AfterJob
继承 Parent Job
如果一组 Job 具有类似但不完全相同的配置,那么定义一个 “parent” Job 可能会有帮助,具体的 Job 实例可以从该 Job 继承属性。类似于 Java 中的类继承,“child” Job 将其元素和属性与 parent Job 的元素和属性相结合。
在下面的例子中,baseJob 是一个抽象的 Job 定义,它只定义了一个 listener 列表。Job(job1)是一个具体的定义,它继承了 baseJob 的 listener 列表,并将其与自己的 listener 列表合并,产生了一个具有两个 listener 和一个 Step(step1)的 Job。
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</job>
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</job>更详细的信息见 继承 Parent Step 一节。
JobParametersValidator
在XML命名空间中声明的 job 或使用 AbstractJob 的任何子类,可以在运行时为 job 参数选择性地声明一个验证器(validator)。例如,当你需要断言一个 job 在启动时带有所有的强制参数时,这很有用。有一个 DefaultJobParametersValidator,你可以用它来约束简单的强制性和可选性参数的组合。对于更复杂的约束,你可以自己实现这个接口。
The configuration of a validator is supported through the XML namespace through a child element of the job, as the following example shows:
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="parametersValidator"/>
</job>You can specify the validator as a reference (as shown earlier) or as a nested bean
definition in the beans namespace.
The configuration of a validator is supported through the Java builders:
@Bean
public Job job1(JobRepository jobRepository) {
return new JobBuilder("job1", jobRepository)
.validator(parametersValidator())
...
.build();
}
Java 配置
Spring 3 带来了用Java而不是XML配置应用程序的能力。从Spring Batch 2.2.0开始,你可以通过使用相同的Java配置来配置批处理作业。基于Java的配置有三个组件:@EnableBatchProcessing 注解和两个 builder。
@EnableBatchProcessing 注解的工作方式与 Spring 家族中的其他 @Enable* 注解类似。在这种情况下,@EnableBatchProcessing 为构建批处理作业提供了一个基础配置。在这个基础配置中,除了一些 bean 可以被自动注入外,还创建了 StepScope 和 JobScope 的实例:
-
JobRepository: 名为jobRepository的 bean。 -
JobLauncher: 名为jobLauncher的 bean。 -
JobRegistry: 名为jobRegistry的 bean。 -
JobExplorer: 名为jobExplorer的 bean。 -
JobOperator: 名为jobOperator的 bean。
默认实现提供了前面列表中提到的 Bean,并要求在context中提供一个 DataSource 和一个 PlatformTransactionManager 作为 Bean。数据源和事务管理器被 JobRepository 和 JobExplorer 实例所使用。默认情况下,名为 dataSource 的数据源和名为 transactionManager 的事务管理器将被使用。你可以通过使用 @EnableBatchProcessing 注解的属性来定制这些Bean中的任何一个。下面的例子显示了如何提供一个自定义的数据源和事务管理器:
@Configuration
@EnableBatchProcessing(dataSourceRef = "batchDataSource", transactionManagerRef = "batchTransactionManager")
public class MyJobConfiguration {
@Bean
public DataSource batchDataSource() {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.HSQL)
.addScript("/org/springframework/batch/core/schema-hsqldb.sql")
.generateUniqueName(true).build();
}
@Bean
public JdbcTransactionManager batchTransactionManager(DataSource dataSource) {
return new JdbcTransactionManager(dataSource);
}
public Job job(JobRepository jobRepository) {
return new JobBuilder("myJob", jobRepository)
//define job flow as needed
.build();
}
}
只有一个配置类需要有 @EnableBatchProcessing 注解。一旦你有一个用它注解的类,你就有了前面描述的所有配置。
|
从 v5.0 开始,通过 DefaultBatchConfiguration 类提供了另一种配置基础架构 bean 的编程式方式。这个类提供了与 @EnableBatchProcessing 所提供的相同的Bean,可以作为一个基类来配置批处理作业。下面的片段是一个如何使用它的典型例子:
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// define job flow as needed
.build();
}
}
数据源和事务管理器将从应用程序context中解析,并在 job repository 和 job explorer 上设置。你可以通过覆盖所需的 setter 来定制任何基础设施Bean的配置。下面的例子显示了如何定制字符编码:
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// define job flow as needed
.build();
}
@Override
protected Charset getCharset() {
return StandardCharsets.ISO_8859_1;
}
}
@EnableBatchProcessing 不应与 DefaultBatchConfiguration 一起使用。你应该通过 @EnableBatchProcessing 使用配置 Spring Batch 的声明方式,或者使用扩展 DefaultBatchConfiguration 的编程方式,但不能同时使用两种方式。
|
配置 JobRepository
当使用 @EnableBatchProcessing 时,为你提供了一个 JobRepository。本节描述了如何配置你自己的。
如前所述, JobRepository 用于 Spring Batch 中各种持久化domain对象的基本CRUD操作,如 JobExecution 和 StepExecution。许多主要的框架功能都需要它,如 JobLauncher、Job 和 Step。
batch 命名空间抽象了 JobRepository 实现及其合作者的许多实现细节。然而,仍有一些配置选项可用,如下面的例子所示:
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>除了 id 之外,前面列出的配置选项都不是必须的。如果没有设置,就会使用前面显示的默认值。 max-varchar-length 的默认值是 2500,这是 示例 schema
脚本 中 long VARCHAR 列的长度。
除了 dataSource 和 transactionManager 之外,前面列出的配置选项都不是必需的。如果没有设置,则使用前面显示的默认值。最大 varchar 长度默认为 2500,这是 示例 schema 脚本 中 long VARCHAR 列的长度。
JobRepository 的事务配置
如果使用命名空间或提供的 FactoryBean,transactional advice 会围绕 repository 自动创建。这是为了确保批处理元数据,包括失败后重新启动所需的状态,都能正确地持久化。如果 repository 方法不是事务性的,框架的行为就不能很好地定义。create* 方法属性中的隔离级别是单独指定的,以确保在 job 启动时,如果两个进程试图同时启动同一个 job,只有一个成功。该方法的默认隔离级别是 SERIALIZABLE,这是相当积极的。READ_COMMITTED 通常也同样好用。如果两个进程不可能以这种方式发生碰撞,READ_UNCOMMITTED 也不错。然而,由于对 create* 方法的调用相当短,只要数据库平台支持,SERIALIZED 不太可能导致问题。然而,你可以覆盖这个设置。
下面的例子显示了如何在XML中覆盖隔离级别:
<job-repository id="jobRepository"
isolation-level-for-create="REPEATABLE_READ" />下面的例子显示了如何在Java中覆盖隔离级别:
@Configuration
@EnableBatchProcessing(isolationLevelForCreate = "ISOLATION_REPEATABLE_READ")
public class MyJobConfiguration {
// job definition
}
如果不使用命名空间,你还必须通过使用AOP来配置 repository 的事务行为。
下面的例子显示了如何在XML中配置 repository 的事务性行为:
<aop:config>
<aop:advisor
pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>你几乎可以按原样使用前面的片段,几乎不做任何改动。记住要包括适当的命名空间声明,并确保 spring-tx 和 spring-aop(或整个Spring)在classpath上。
下面的例子显示了如何在Java中配置 repository 的事务性行为:
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}
修改表前缀
JobRepository 的另一个可修改的属性是元数据表的表前缀。默认情况下,它们都是以 BATCH_ 为前缀。 BATCH_JOB_EXECUTION 和 BATCH_STEP_EXECUTION 是两个例子。然而,有一些潜在的原因需要修改这个前缀。如果 schema 名称需要在表名前加上前缀,或者在同一个 schema 中需要多套元数据表,则需要改变表的前缀。
下面的例子显示了如何在XML中改变表的前缀:
<job-repository id="jobRepository"
table-prefix="SYSTEM.TEST_" />下面的例子显示了如何在Java中改变表的前缀:
@Configuration
@EnableBatchProcessing(tablePrefix = "SYSTEM.TEST_")
public class MyJobConfiguration {
// job definition
}
鉴于前面的变化,对元数据表的每个查询都以 SYSTEM.TEST_ 为前缀。BATCH_JOB_EXECUTION 被称为 SYSTEM.TEST_JOB_EXECUTION。
| 只有表的前缀是可配置的。表和列的名称是不可配置的。 |
Repository 中的非标准数据库类型
如果你使用的数据库平台不在支持的平台列表中,你也许可以使用支持的类型之一,如果SQL的变体足够接近。要做到这一点,你可以使用原始的 JobRepositoryFactoryBean 而不是命名空间的快捷方式,并使用它将数据库类型设置为最接近的匹配。
下面的例子显示了如何使用 JobRepositoryFactoryBean 将数据库类型设置为XML中最接近的匹配:
<bean id="jobRepository" class="org...JobRepositoryFactoryBean">
<property name="databaseType" value="db2"/>
<property name="dataSource" ref="dataSource"/>
</bean>下面的例子显示了如何使用 JobRepositoryFactoryBean 将数据库类型设置为Java中最接近的匹配:
@Bean
public JobRepository jobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}
如果没有指定数据库类型,JobRepositoryFactoryBean 会尝试从 DataSource 中自动检测数据库类型。平台之间的主要差异主要体现在主键的递增策略上,所以通常也需要覆盖 incrementerFactory (通过使用Spring框架的一个标准实现)。
如果这样也不行,或者你没有使用 RDBMS,唯一的选择可能是实现 SimpleJobRepository 所依赖的各种 Dao 接口,并以正常的Spring方式手动注入一个。
配置 JobLauncher
当你使用 @EnableBatchProcessing 时,一个 JobRegistry 会提供给你。本节描述了如何配置你自己的。
JobLauncher 接口的最基本实现是 TaskExecutorJobLauncher。它唯一需要依赖的是一个 JobRepository(需要获得 execution)。
下面的例子显示了XML中的 TaskExecutorJobLauncher:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>下面的例子显示了Java中的 TaskExecutorJobLauncher:
...
@Bean
public JobLauncher jobLauncher() throws Exception {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
...
一旦获得一个 JobExecution,它就被传递给 Job 的 execution 方法,最终将 JobExecution 返回给调用者,如下图所示:

该序列很直接,从调度器启动时效果很好。然而,当试图从HTTP请求中启动时就会出现问题。在这种情况下,启动需要异步进行,以便 TaskExecutorJobLauncher 立即返回给它的调用者。这是因为在长时间运行的进程(如批处理作业)所需的时间内保持HTTP请求的开放不是好的做法。下面的图片显示了一个序列的例子:
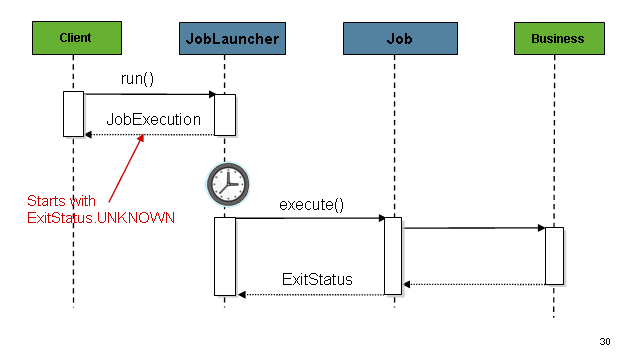
你可以配置 TaskExecutorJobLauncher,通过配置一个 TaskExecutor 来允许这种情况的发生。
下面的XML例子配置了一个 TaskExecutorJobLauncher,使其立即返回:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>下面的Java例子将一个 TaskExecutorJobLauncher 配置为立即返回:
@Bean
public JobLauncher jobLauncher() {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
你可以使用spring TaskExecutor 接口的任何实现来控制 job 的异步执行方式。
运行 Job
至少,启动一个批处理 job 需要两样东西:要启动的 Job 和一个 JobLauncher。两者可以包含在同一个 context,也可以是不同的 context。例如,如果你从命令行启动 job,就会为每个 Job 实例化一个新的 JVM。因此,每个 Job 都有自己的 JobLauncher。然而,如果你从一个在 HttpRequest scope 内的Web容器中运行,通常有一个 JobLauncher(配置为异步 job 启动),多个请求调用它来启动它们的 job。
从命令行运行 Job
如果你想从企业调度器中运行你的job,命令行是主要的界面。这是因为大多数调度器(Quartz 除外,除非使用 NativeJob)直接与操作系统进程工作,主要是用shell脚本启动。除了shell脚本,还有很多方法可以启动Java进程,比如Perl、Ruby,甚至是Ant或Maven等构建工具。不过,由于大多数人对shell脚本很熟悉,本例重点介绍shell脚本。
CommandLineJobRunner
因为启动 job 的脚本必须启动一个Java虚拟机,所以需要有一个带有 main 方法的类来作为主要入口。Spring Batch 提供了一个实现,可以达到这个目的:CommandLineJobRunner。请注意,这只是启动你的应用程序的一种方式。有很多方法可以启动一个Java进程,这个类不应该被看作是决定性的。CommandLineJobRunner 执行四个任务:
-
加载适当的
ApplicationContext。 -
将命令行参数解析为
JobParameters。 -
根据参数找到合适的 job。
-
使用 application context 中提供的
JobLauncher来启动job。
所有这些任务都是只用传入的参数完成的。下表描述了所需的参数:
|
用于创建 |
|
要运行的 job 的名称。 |
这些参数必须被传入,路径在前,名称在后。在这些参数之后的所有参数都被认为是 job 参数,被变成 JobParameters 对象,并且必须是 name=value 的格式。
下面的例子显示了一个 date 作为 job 参数传递给一个用XML定义的 job:
<bash$ java CommandLineJobRunner endOfDayJob.xml endOfDay schedule.date=2007-05-05,java.time.LocalDate下面的例子显示了一个 date 作为 job 参数传递给一个用Java定义的 job:
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date=2007-05-05,java.time.LocalDate|
默认情况下, 在下面的例子中, 你可以通过使用一个自定义的 |
In most cases, you would want to use a manifest to declare your main class in a jar. However,
for simplicity, the class was used directly. This example uses the EndOfDay
example from the The Domain Language of Batch. The first
argument is endOfDayJob.xml, which is the Spring ApplicationContext that contains the
Job. The second argument, endOfDay, represents the job name. The final argument,
schedule.date=2007-05-05,java.time.LocalDate, is converted into a JobParameter object of type
java.time.LocalDate.
The following example shows a sample configuration for endOfDay in XML:
<job id="endOfDay">
<step id="step1" parent="simpleStep" />
</job>
<!-- Launcher details removed for clarity -->
<beans:bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher" />In most cases, you would want to use a manifest to declare your main class in a jar. However,
for simplicity, the class was used directly. This example uses the EndOfDay
example from the The Domain Language of Batch. The first
argument is io.spring.EndOfDayJobConfiguration, which is the fully qualified class name
to the configuration class that contains the Job. The second argument, endOfDay, represents
the job name. The final argument, schedule.date=2007-05-05,java.time.LocalDate, is converted
into a JobParameter object of type java.time.LocalDate.
The following example shows a sample configuration for endOfDay in Java:
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Bean
public Job endOfDay(JobRepository jobRepository, Step step1) {
return new JobBuilder("endOfDay", jobRepository)
.start(step1)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> null, transactionManager)
.build();
}
}
前面的例子过于简单,因为在 Spring Batch 中运行批处理 job 的要求还有很多,但它有助于显示 CommandLineJobRunner 的两个主要要求: Job 和 JobLauncher。
退出代码
当从命令行启动批处理 job 时,经常使用企业调度器。大多数调度器是相当愚蠢的,只在进程层面工作。这意味着他们只知道一些操作系统的进程(比如他们调用的shell脚本)。在这种情况下,向调度器反馈 job 成功或失败的唯一方法是通过返回代码。返回代码是一个数字,由进程返回给调度器,以表示运行的结果。在最简单的情况下,0 是成功,1 是失败。然而,可能会有更复杂的情况,比如 "如果工作A返回4,就踢掉工作B,如果返回5,就踢掉工作C。" 这种类型的行为是在调度器层面上配置的,但是像 Spring Batch 这样的处理框架必须提供一种方法来返回特定批处理 job 的退出代码的数字表示。在 Spring Batch 中,这被封装在 ExitStatus 中,这将在第5章中详细介绍。为了讨论退出代码,唯一需要知道的是 ExitStatus 有一个退出代码属性,该属性由框架(或开发者)设置,并作为 JobLauncher 返回的 JobExecution 的一部分被返回。CommandLineJobRunner 通过使用 ExitCodeMapper 接口将这个字符串值转换为一个数字:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
ExitCodeMapper 的基本契约是,给定一个字符串退出代码,将返回一个数字表示。job runner 使用的默认实现是 SimpleJvmExitCodeMapper,完成时返回 0,通用错误时返回 1,任何 job runner 错误时返回 2,如无法在提供的context中找到一个 Job。如果需要比上述三个值更复杂的东西,必须提供 ExitCodeMapper 接口的自定义实现。因为 CommandLineJobRunner 是创建 ApplicationContext 的类,因此,不能被 "相互注入",任何需要被覆盖的值都必须是自动注入。这意味着如果在 BeanFactory 中找到 ExitCodeMapper 的实现,它将在context创建后被注入到 runner 中。提供你自己的 ExitCodeMapper 所需要做的就是将实现声明为根级 bean,并确保它是被 runner 加载的 ApplicationContext 的一部分。
从 Web 容器中运行 Job
历史上,离线处理(如批处理作业)一直是从命令行启动的,如前所述。然而,在很多情况下,从 HttpRequest 启动是一个更好的选择。许多这样的用例包括报告、临时作业运行和 web 应用支持。因为批处理作业(根据定义)是长期运行的,所以最重要的关注点是异步启动作业:
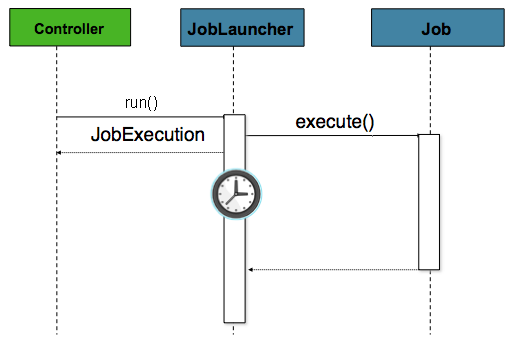
本例中的控制器是一个Spring MVC controller。关于 Spring MVC 的更多信息,请参见《Spring框架参考指南》。controller 通过使用 JobLauncher 来启动一个 Job,这个 JobLauncher 被配置为 异步 启动,并立即返回一个 JobExecution。该 Job 可能仍在运行。然而,这种非阻塞行为让 controller 立即返回,这在处理 HttpRequest 时是必需的。下面的列表显示了一个例子:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
高级元数据的使用
到目前为止,我们已经讨论了 JobLauncher 和 JobRepository 这两个接口。它们共同代表了 job 的简单启动和批处理 domain 对象的基本CRUD操作:
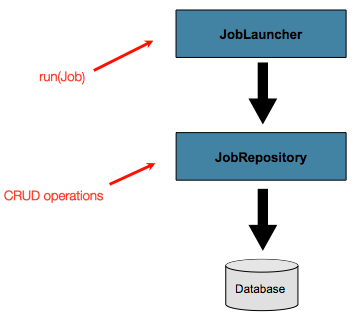
一个 JobLauncher 使用 JobRepository 来创建新的 JobExecution 对象并运行它们。Job 和 Step 的实现后来使用相同的 JobRepository 在 Job 的运行过程中对相同的执行进行基本更新。这些基本操作对于简单的场景来说已经足够了。然而,在一个有数百个批处理作业和复杂调度要求的大型批处理环境中,需要对元数据进行更高级的访问:
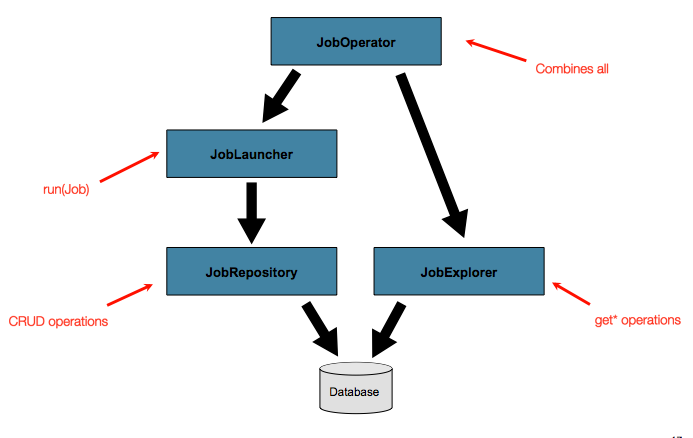
接下来的章节将讨论 JobExplorer 和 JobOperator 接口,它们增加了查询和控制元数据的额外功能。
查询 Repository
在任何高级功能之前,最基本的需求是查询 repository 的现有执行情况的能力。这个功能是由 JobExplorer 接口提供的:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}
从它的方法签名中可以看出,JobExplorer 是 JobRepository 的只读版本,而且和 JobRepository 一样,它可以通过使用工厂 Bean 轻松配置。
下面的例子显示了如何在XML中配置一个 JobExplorer:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />下面的例子显示了如何在Java中配置一个 JobExplorer:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
...
在本章的前面,我们注意到你可以修改 JobRepository 的表前缀,以允许不同的版本或schema。因为 JobExplorer 与相同的表一起工作,它也需要设置前缀的能力。
下面的例子显示了如何在XML中为 JobExplorer 设置表前缀:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/>下面的例子显示了如何在 Java 中为 JobExplorer 设置表格前缀:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...
JobRegistry
JobRegistry(以及它的父接口 JobLocator)不是强制性的,但是如果你想跟踪 context 中哪些 job 是可用的,它可能会很有用。当 job 在其他地方被创建时(例如,在子 context 中),它对于在应用程序 context 中集中收集 job 也很有用。你也可以使用自定义的 JobRegistry 实现来操作被注册的 job 的名称和其他属性。框架只提供了一个实现,它是基于一个简单的从 job 名称到 job 实例的映射。
下面的例子显示了如何为一个用XML定义的 job 包含一个 JobRegistry:
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" />当使用 @EnableBatchProcessing 时,将为你提供一个 JobRegistry。下面的例子显示了如何配置你自己的 JobRegistry:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the bean in the DefaultBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...
你可以通过两种方式填充 JobRegistry:使用 Bean Post processor 或使用注册的生命周期组件。接下来的章节将描述这两种机制。
JobRegistryBeanPostProcessor
这是一个 bean post-processor,可以在创建时注册所有 job。
下面的例子显示了如何为一个用XML定义的 job 包含 JobRegistryBeanPostProcessor:
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>下面的例子显示了如何为一个用 Java 定义的 job 包含 JobRegistryBeanPostProcessor:
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
}
虽然不是严格意义上的必要,但例子中的 post-processor 已经被赋予了一个 id,以便它可以被包含在子context中(例如,作为父bean的定义),并使所有在那里创建的 job 也被自动注册。
AutomaticJobRegistrar
这是一个生命周期组件,它创建了子context,并在这些context中注册了job,因为它们被创建。这样做的一个好处是,虽然子context中的job名称在注册表中仍然必须是全局唯一的,但它们的依赖关系可以有 "自然" 的名称。因此,例如,你可以创建一组 XML 配置文件,每个文件只有一个job,但都有不同的 ItemReader 定义,具有相同的 bean 名称,如 reader。如果所有这些文件都被导入到同一个context中,reader 的定义就会发生冲突并相互覆盖,但是,有了自动注册器,这种情况就可以避免了。这使得整合从一个应用程序的不同模块中贡献出来的job变得更加容易。
下面的例子显示了如何为一个用 XML 定义的 job 包含 AutomaticJobRegistrar:
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>下面的例子显示了如何为一个用 Java 定义的 job 包含 AutomaticJobRegistrar:
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
}
注册器有两个强制性的属性:一个 ApplicationContextFactory 数组(在前面的例子中从一个方便的工厂bean中创建)和一个 JobLoader。JobLoader 负责管理子 context 的生命周期并在 JobRegistry 中注册 job。
ApplicationContextFactory 负责创建子context。最常见的用法是(如前面的例子)使用一个 ClassPathXmlApplicationContextFactory。这个工厂的一个特点是,默认情况下,它把一些配置从 parent context复制到子context。因此,例如,你不需要在子代中重新定义 PropertyPlaceholderConfigurer 或AOP配置,只要它与 parent 相同。
你可以将 AutomaticJobRegistrar 与 JobRegistryBeanPostProcessor 结合使用(只要你同时使用 DefaultJobLoader)。例如,如果在主父 context 和子 context 中都有定义的job,这可能是可取的。
JobOperator
如前所述,JobRepository 提供了对元数据的CRUD操作,而 JobExplorer 提供了对元数据的只读操作。然而,这些操作在一起用于执行常见的监控任务时是最有用的,比如停止、重启或总结一个Job,这也是批处理运维通常做的。Spring Batch在 JobOperator 接口中提供了这些类型的操作:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
前面的操作代表了许多不同接口的方法,如 JobLauncher, JobRepository, JobExplorer 和 JobRegistry。由于这个原因,所提供的 JobOperator 的实现(SimpleJobOperator)有许多依赖。
下面的例子显示了XML中 SimpleJobOperator 的一个典型的Bean定义:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>下面的例子显示了Java中 SimpleJobOperator 的一个典型的bean定义:
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry,
JobLauncher jobLauncher) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}
从 5.0 版本开始,@EnableBatchProcessing 注解会自动在 application context 中注册一个 job operator bean。
| 如果你在 job repository 上设置了表前缀,不要忘记在 job explorer 上也设置。 |
JobParametersIncrementer
JobOperator 上的大多数方法是不言自明的,你可以在 接口的 Javadoc 中找到更详细的解释。然而,startNextInstance 方法值得注意。这个方法总是启动一个新的 Job 实例。如果在 JobExecution 中出现了严重的问题,而 Job 需要从头开始重新启动,那么这个方法就会非常有用。与 JobLauncher(它需要一个新的 JobParameters 对象来触发一个新的 JobInstance)不同,如果参数与之前的任何一组参数不同,startNextInstance 方法使用与 Job 绑定的 JobParametersIncrementer 来强制 Job 进入一个新的实例:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
JobParametersIncrementer 给定一个 JobParameters 对象,它通过递增它可能包含的任何必要值来返回 "下一个" JobParameters 对象。这个策略很有用,因为框架没有办法知道 JobParameters 的哪些变化使它成为 "下一个" 实例。例如,如果 JobParameters 中唯一的值是一个date,并且应该创建下一个实例,那么这个值应该递增一天还是一周(例如,如果 job 是每周的)?对于任何有助于识别 Job 的数值也可以这样说,正如下面的例子所示:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}
在这个例子中,以 run.id 为key的值被用来区分 JobInstances。如果传入的 JobParameters 是空的,可以认为该 Job 以前从未运行过,因此,可以返回其初始状态。但是,如果不是这样,就会得到旧的值,并递增1,然后返回。
For jobs defined in XML, you can associate an incrementer with a Job through the
incrementer attribute in the namespace, as follows:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>For jobs defined in Java, you can associate an incrementer with a Job through the
incrementer method provided in the builders, as follows:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.incrementer(sampleIncrementer())
...
.build();
}
停止 Job
JobOperator 最常见的用例之一是优雅地停止一个 Job:
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());
关闭不是立即的,因为没有办法强制立即关闭,特别是如果当前执行的是框架无法控制的开发者代码,比如一个业务服务。然而,一旦控制权返回给框架,它就会将当前 StepExecution 的状态设置为 BatchStatus.STOPPED,并将其保存,在结束前对 JobExecution 做同样的处理。
中断 Job
FAILED 的 job 执行可以被重新启动(如果该 Job 是可重新启动的)。一个状态为 ABANDONED 的 job 执行不能被框架重新启动。ABANDONED 状态也被用于step执行中,以便在重新启动的 job 执行中把它们标记为可跳过的(skippable)。如果一个 job 正在运行,并遇到一个在之前失败的 job 执行中被标记为 ABANDONED 的step,它就会进入下一个step(由 job 流程定义和step执行退出状态决定)。
如果进程死亡(kill -9 或服务器故障),job 当然就不运行了,但 JobRepository 没有办法知道,因为在进程死亡之前没有人告诉它。你必须手动告诉它,你知道执行失败或者应该被认为是中止的(将其状态改为 FAILED 或 ABANDONED)。这是一个业务决定,没有办法将其自动化。只有当它可以重启并且你知道重启的数据是有效的时候,才把状态改为 FAILED。