Spring Cloud Stream Kafka 中的事务简介
本系列教程重点介绍如何在 Spring Cloud Stream Kafka 应用中处理事务。涵盖了使用 Spring Cloud Stream 和 Apache Kafka 开发事务应用的许多底层细节。
基本组成
Spring Cloud Stream Kafka 应用中事务的基础支持主要来自于 Apache Kafka 本身和 Spring for Apache Kafka 库。然而,这个博客系列是关于如何在 Spring Cloud Stream 中使用这种支持。如果你熟悉 Apache Kafka 中的事务原理,以及 Spring for Apache Kafka 是如何以 Spring 的方式使用它的,那么这个系列将感觉像是自己的领域。
Apache Kafka 提供了基础事务支持,而 Spring for Apache Kafka(又称 Spring Kafka)库则在 Spring 侧扩展了这一支持,使 Spring 开发人员可以更自然地依赖 Spring Framework 中提供的传统事务支持来使用它。Spring Cloud Stream 中的 Kafka Binder(绑定器)进一步加强了 Spring 对 Apache Kafka 的支持,使在 Spring Cloud Stream Kafka 应用中使用相同的支持成为可能。在本系列教程的第一部分中,将简要介绍 Kafka 事务、一些有助于依赖事务的用例分析,以及 Apache Kafka 和 Spring 生态系统中的事务构建模块。
在许多用例中,都需要在 Apache Kafka 中以事务方式发布、消费和处理记录。在生产者启动的应用或实现消费-处理-生产(consume-process-produce)模式的流程中以事务方式生产记录时,记录会以原子方式写入 Kafka。如果出了问题,整个流程会回滚,事务不会提交。需要记住的一点是,Apache Kafka 与支持事务的关系数据库不同,后者在发生事务回滚时不会持续记录,而 Apache Kafka 仍会将记录发布到 Topic 分区(Partition)。这种行为是由于 Apache Kafka 基于日志的只附加、不可变的基本架构造成的,它不允许对记录进行任何修改,例如在将记录添加到记录日志后再将其删除。有人可能会问,使用事务有什么好处,因为当事务中止时,记录可能会发布到 Topic 分区,从而可能导致消费者看到这些记录。但是,具有适当 隔离级别 的消费者永远不会看到回滚的记录,即使回滚事务的记录在 Topic 分区中。因此,从端到端的角度来看,整个过程都得到了完全的事务保证。
事务用例
在 Kafka 应用中,事务通常会增加大量开销。在 Apache Kafka 中使用事务时,每条记录都必须向记录添加特殊事务日志,向特殊事务状态 Topic 发送事务标记,等等。所有这些步骤都会耗费时间和空间,增加整体延迟。因此,每个应用都必须通过分析用例来仔细研究是否需要事务支持。
事务提供了一种主要保护数据的方法,以提供 ACID 功能。它通过提供原子性、一致性、数据隔离和持久性来确保数据完整性。
在当今企业的一些关键任务用例中,使用事务并依赖其带来的 ACID 语义是非常可取的。关于何时使用事务并证明其带来的开销是合理的,并没有简单明了的答案。你必须审视应用程序,评估其中的利害关系。事务的典型例子是任何需要处理财务数据的应用。Bob 向 Alice 汇款,从 Bob 的账户中扣款,并将金额存入 Alice 的账户。如果在这个过程中出现任何差错,整个过程都会回滚,就像什么都没发生一样,因为我们不希望流程处于杂乱无章的状态。如果流程从 Bob 的账户中扣款,但 Alice 却没有入账(反之亦然),那就有问题了。从 Apache Kafka 的角度来看,这里有几个问题。首先,一条消息传递给 Kafka 处理器,用于从 Bob 的账户中扣款和接收者的信息。处理器对消息进行处理,然后发送另一条消息到另一个 Topic,表示从 Bob 的账户中扣款已经完成。随后,又发送一条消息表示 Alice 现在已经收到存款。这个过程中的各种操作需要复杂的协调,以确保一切按预期进行。任何时候,如果我们有类似的多个相关事件,事务都可以帮助确保数据完整性并提供 ACID 语义。在这个示例中,单个事件并没有太大的独立意义,但它们共同构成了整个流程,需要事务性来确保数据完整性。
任何时候我们都可以使用“消费-处理-发布”模式来完成关键任务,在这种模式下,如果一个组件出现故障,整个处理器就需要像没有发生故障一样运行,而使用事务就是一种潜在的解决方案。
其他领域的更多高级示例
- 试想一下,一个机票预订系统需要发布一个包含多段行程的预订信息。如果由于某种原因,系统无法发布整个预订信息,则需要中止流程并重新开始。
- 一家经纪公司向清算所发送包含多个买入订单的请求。假设该流程无法将单个订单作为单个原子单元发布到清算所使用的消息系统。在这种情况下,经纪公司必须重新发送订单。
- 向保险公司发送病人化验数据的医疗计费系统必须将病人的各种相关化验数据发布到消息系统中。
- 在线游戏系统需要跟踪玩家在游戏中的位置,并通过事务处理将其发送到中央服务器,以确保所有玩家看到的是正确的坐标,而不是部分更新的位置。
- 零售商的库存补货系统需要将各种相关产品的状态信息作为单一原子单元发送。
- 在线电子商务订购系统,在单个原子聚合操作中发布订单详细信息(如订单条目、账户持有人信息、发货信息等)。
与外部数据库同步
在另一类用例中,当你需要与其他事务系统同步时,事务会变得非常方便。除了向 Kafka 发布数据外,假设你还必须在关系数据库中持久化记录或某些派生信息,而这一切都需要在单个原子操作中完成。如果一个系统发送数据失败,我们就必须回滚。如果每次发布到 Kafka 的只有一条记录,没有其他任何相关操作,那么就不需要使用事务,我们将在本系列教程的下一部分看到这一点。不过,即使你只向 Kafka Topic 发布一次,但在同一流程中使用了关系数据库操作,也有必要使用事务来确保数据完整性。
发布到多个 Kafka Topic
纯生产者应用中事务的另一个用例是发布到多个 Kafka Topic。假设你有一些关键通知形式的关键业务数据(如订单详情),你希望发布到多个 Kafka Topic,订单详情的一部分发布到 order Topic,另一部分发布到 shipping Topic。在这种情况下,我们可以使用事务来确保端到端的数据完整性。
概括上述事务性用例
上述使用案例并不是必须进行事务处理的全部案例。当今企业中还存在许多其他使用案例,它们与我们所研究的使用案例的主旨并无太大区别,都需要在消息传递系统中进行事务处理。
以下列表总结了 Apache Kafka 中的事务可以发挥作用的一般用例:
- 消费-处理-发布系统,它需要将记录作为单一原子单元发布,并提供精确的一次语义交付保证。
- 多个相关的发布事件,单独来看没有意义。
- 以单个原子单位向多个 Topic 发布数据。
- 与外部事务管理器同步。
下面是所有这些不同情况的图示。它涵盖了我们上面考虑过的各种情况,如消费-处理-生产、多个生产者、与外部事务同步等。一个处理器从一个入站 Topic 消耗数据,执行业务逻辑,将一些信息持久化到数据库系统,然后发布到多个 Kafka Topic。
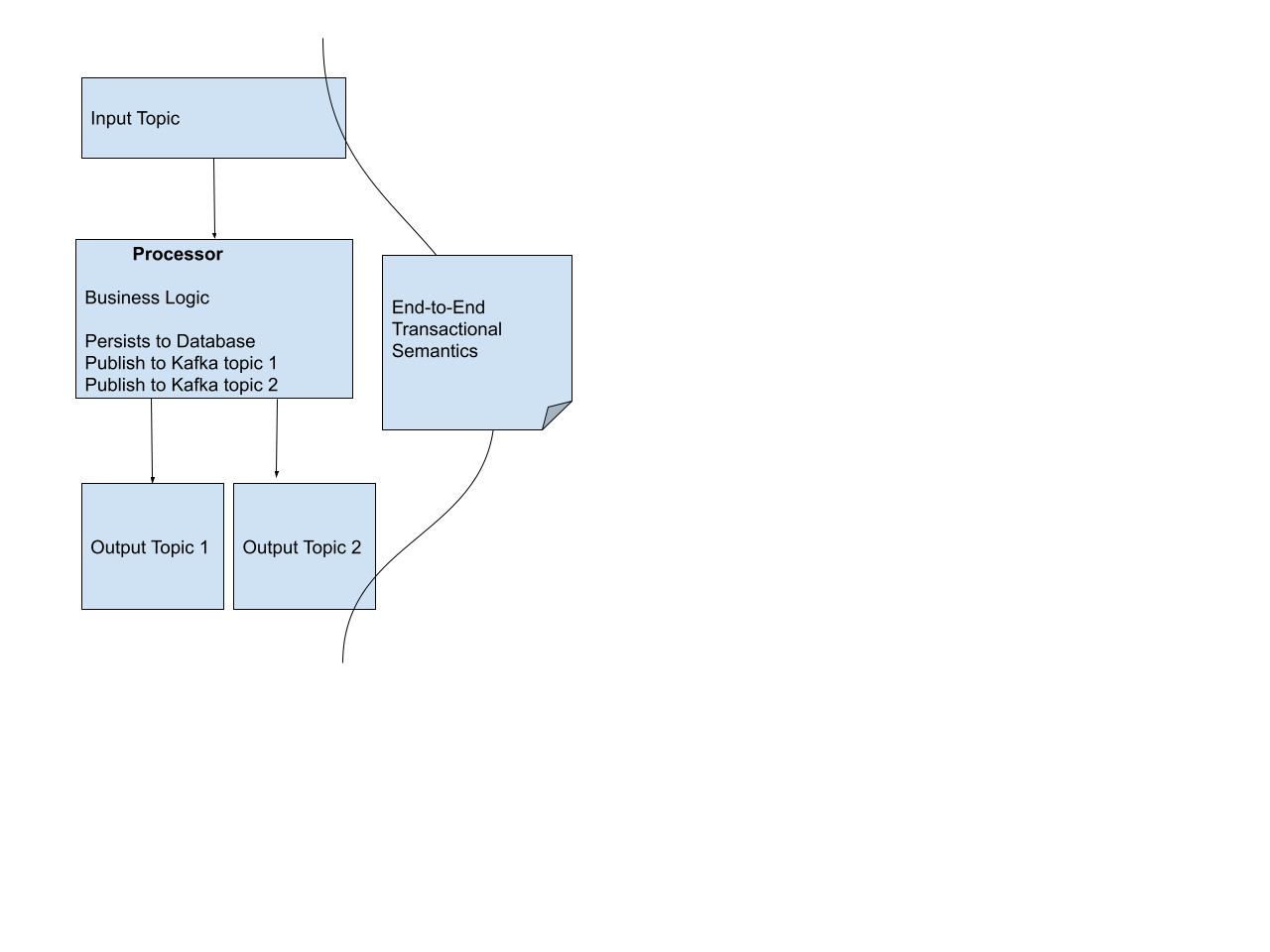
Apache Kafka 中的事务
有很多文献可以研究 Apache Kafka 中事务如何工作的底层细节,这里有一篇 文章 可以介绍这些细节。不过,简单了解一下从高层次实现事务性的 Kafka 客户端 API 还是值得的。需要注意的一点是,说到普通消费者,Kafka 中并没有所谓的事务消费者,但有事务感知消费者。消费者通过设置隔离级别来实现事务感知。默认情况下,Kafka 消费者可以看到上游生产者的所有记录,甚至是未提交的记录,因为 Kafka 消费者的默认隔离级别是 read_uncommitted。Kafka 消费者必须使用 read_committed 的隔离级别来提供端到端的事务语义。我们将在本系列教程的后续章节中了解如何在 Spring Cloud Stream 中实现这一点。
在生产者方面,应用需要依赖 Kafka 客户端提供的一些 API 方法。让我们来看看其中重要的几种。
要使应用程序具有事务性,Kafka 客户端需要一个事务 ID。应用通过名为 transactional.id 的 Kafka 生产者属性提供该 ID,事务协调器通过注册该 ID 来启动事务。事务协调器使用该 ID 跟踪事务的各个方面,如初始化、持续进展、提交等。
以下列表总结了与事务相关的重要生产者 API 方法。
- Producer#initTransactions() - 每个生产者调用一次,以启动事务支持。初始化 Kafka 事务。
- Producer#beginTransaction() - 在发送记录前开始事务。
- Producer#sendOffsetsToTransaction() - 将消耗的记录偏移量发送给事务。
- Producer#commitTransaction() - 提交事务。
- Producer#abortTransaction() - 终止事务。
在发送记录之前,我们需要初始化并开始事务。然后,它继续进行数据处理。如果我们消费了一条记录来进行发布,我们必须使用生产者将消费的记录的偏移量发送到事务中。之后,事务的提交或中止操作可以继续(commitTransaction 或 abortTransaction)。当我们调用 commitTransaction 方法时,偏移量会由 Kafka 客户端以原子方式发送到 consumer_offsets Topic 中。
Spring for Apache Kafka 中的事务支持
当使用像 Spring for Apache Kafka 或 Spring Cloud Stream Kafka binder 这样依赖于它的框架时,它们带来的好处是允许应用程序将主要精力放在业务逻辑上,因为这些框架会处理我们在上文看到的底层模板事务序列。使用 Spring for Apache Kafka 或其他框架(如使用它的 Spring Cloud Stream)会带来很多好处,因为这样我们就不必担心编写底层模板序列(如上所述),从而确保所有事务步骤都能成功。可以想象,这里有很多活动部件,如果省略了某个步骤或没有按照预期完成某个步骤,就会导致应用程序容易出错。就 Spring 而言,我们提到的框架会代表应用开发人员处理这些问题。让我们简单了解一下它是如何做到这一点的。
Spring for Apache Kafka 框架通过提供 Spring 开发人员熟悉的一致的事务编程模型,隐藏了所有这些底层细节。因此,在使用 Spring for Apache Kafka 或其他框架(如 Spring Cloud Stream)时,应用程序只需专注于应用的业务逻辑,而无需处理复杂的底层事务相关事宜。
KafkaTransactionManager
Spring for Apache Kafka 如何提供这种一致的事务编程模型?简而言之,Spring 开发人员传统上使用事务注解或编程方法,例如直接在应用程序中使用事务模板(TransactionTemplate)来创建本地事务。这些机制需要事务管理器来实现事务处理。Spring for Apache Kafka 提供了事务管理器实现。KafkaTransactionManager 是 Spring Framework 中 PlatformTransactionManager 的一种实现。你可以将该事务管理器与事务注解(Transactional)一起使用,也可以在本地事务中使用事务模板(TransactionTemplate)。KafkaTransactionManager 使用生产者工厂来创建 Kafka 生产者,并提供了开始、提交和回滚事务的 API。
KafkaResourceHolder
Spring for Apache Kafka 还提供了一个 KafkaResourceHolder,用于保存 Kafka 生产者资源。Spring for Apache Kafka 中的 KafkaTemplate 会触发给定生产者工厂在当前线程上绑定 KafkaResourceHolder。在消费者发起的事务中,消息监听容器会进行绑定,生产者工厂与 KafkaTransactionManager 使用的工厂相同。这样,事务就可以使用同一个事务生产者来满足所有发布需求。
除了上述组件,Spring for Apache Kafka 还提供了其他实用工具来处理与事务相关的问题。在本系列的后续章节中,我们将看到其中一些必要的工具。
在本系列教程的第 2 部分中,我们将介绍在 Spring Cloud Stream 应用程序中使用事务的更多实际实施细节。
参考:https://spring.io/blog/2023/09/27/introduction-to-transactions-in-spring-cloud-stream-kafka-applications
